You might have noticed that initdb has a -X/--waldir option to relocate the write-ahead log (pg_wal) directory. This allows the WAL I/O traffic to be on a device different from the default data directory. (This is similar to the use of tablespaces.) If you wish to move the pg_wal (or older pg_xlog) directory to a different device after running initdb, you can simply shut down the database server, move pg_wal to a new location, and create a symbolic link from the data directory to the new pg_wal location.
↧
Bruce Momjian: WAL Directory Location
↧
Ajay Kulkarni: How we are building a self-sustaining open-source business in the cloud era
Today, we are announcing that we have started developing new open-code (or source-available) features that will be made available under the (also new) Timescale License (TSL). You will be able to follow the development of these features on our GitHub.
Some of these new features (“community features”) will be free (i.e., available at no charge) for all users except for the <0.0001% who just offer a hosted “database-as-a-service” version of TimescaleDB. Other features will require a commercial relationship with TimescaleDB to unlock and use for everyone (“enterprise features”). And to be clear, we will also continue to invest in the core of TimescaleDB, which will remain open-source under the Apache 2 license.
Going forward, all new features will be categorized into one of the three following buckets: open-source, community, and enterprise.

Software licenses like the TSL are the new reality for open-source businesses like Timescale. This is because the migration of software workloads to the cloud has changed the open-source software industry. Public clouds currently dominate the space, enabling some of them to treat open-source communities and businesses as free R&D for their own proprietary services.
While this behavior (also known as “strip mining”) is legally permissible within the boundaries of classic open-source licenses, we believe it is not good for the open-source community because it is not sustainable. It makes it impossible to build the independent businesses required to support large-scale open-source projects (without being tied to the whims of a large corporate sponsor with varied interests). We ultimately believe that a self-sustaining business builds better open-source software.
(The new Confluent Community License is another example of an open-source business enacting a new license to counteract strip mining by some of the public clouds.)
In this post we explain what we are doing to address this challenge. We also explain what this might mean for you, an existing or potential TimescaleDB user.
What is TimescaleDB?
TimescaleDB is an open-source time-series database that scales and supports full SQL.
Two years ago, we started working on TimescaleDB to scratch our own itch. We were building another business (an IoT data platform) and were unhappy with many of the existing open-source options: We wanted a time-series database that scaled, yet also supported SQL and the relational data model. We also needed something more reliable than any of the existing time-series databases.
Turns out we weren’t the only ones with this itch. In the 20 months since we launched, the response to TimescaleDB has far surpassed what we expected, with over 1 million downloads, 6,000+ GitHub stars, and mission-critical deployments worldwide. In an industry crowded with database options, TimescaleDB remains unique in offering both SQL and scale for time-series data. In fact, AWS has told us that TimescaleDB is the most requested extension on Amazon RDS. And it’s public knowledge that TimescaleDB is the most requested feature on Azure PostgreSQL.
But today, we face a new challenge: how do we translate all this open-source adoption into a commercially sustainable business?
Can open source be sustainable?
We’d like to be clear: we are strong advocates of open-source software. Open-source software is transparent, flexible, and produces higher-quality code. At its core, TimescaleDB relies fundamentally on open-source PostgreSQL.
Open-source software also builds communities. So many of the building blocks of computing, from programming languages to the Internet, developed because of collaborative communities sharing knowledge across the industry. Collaborative communities build better things.
But open source also introduces its own challenges for long-term sustainability. Many OSS projects start from within and are nurtured by much larger corporations, or develop as community projects relying on external sponsors or foundations for financial support. These backers can be fickle. And building complex software infrastructure requires top-notch engineers, sustained effort, and significant investment.
So to develop a large-scale, technically-complex project and ensure long-term sustainability, Timescale is not only an open-source database project, but also a company.
What options do open-source companies have to make money?
Open-source companies typically sustain themselves financially in three main ways: support, hosting, and open-core licensing. (We’ve written a deeper analysis of these models here.)
We don’t love the support model long-term, even though it accounts for nearly all of our revenue today. Only selling support creates perverse incentives for an open-source company, where making the product easier to use cannibalizes support revenue. Further, the need for support significantly diminishes as workloads migrate to hosted services, including those offered by third-party cloud providers.
We like the hosting model, which also provides a great user experience. But hosting alone has two limitations. First, with a large number of TimescaleDB deployments on premise and at the edge (including deployments ranging from $35 Raspberry Pi’s to monitoring $10 million Cray Supercomputers), hosting can only be part of our answer. Second, the major cloud providers threaten to capture most of the hosted workloads, potentially leaving little for open-source companies.
We also like open-core licensing, but not how it’s often implemented: part open-source, part proprietary closed source. As OSS users ourselves, we don’t like using black-box infrastructure software that we can’t peer into. And as OSS developers, we find that the process of managing two different parallel code repositories is slow, frustrating, and brittle.
TimescaleDB’s approach to long-term sustainability
We’re placing a new emphasis on the long-term sustainability of TimescaleDB, while still addressing the needs and wants of our community. We’ve consulted with our free users, paid customers, advisors, and other industry experts on our approach in order to develop what we believe to be the best path forward for us.
Our existing code will continue to be licensed under the open-source Apache 2 license, and many more OSS-licensed capabilities are in development. But, we also will soon be releasing new “proprietary” features under an open-core model.
Many of these new so-called “proprietary” capabilities can be used for free, with only some more enterprise-relevant capabilities requiring a paid license key to unlock and use. So for that vast 99.9999% of users — just not those cloud providers — a significant portion of the “proprietary” features in TimescaleDB will be both open code and free-to-use at no charge. We view our free “community” features as our way of giving back to the community while protecting against cloud providers.
In the spirit of openness and to solve the “black box code” problem, we are building both our open-source and “proprietary” software in the same repository, and then making the source code for the entire repo available. That is, the entire repository will be “open code” (or “source available”), just not all licensed under an OSI-approved open-source license. This allows TimescaleDB users to inspect, comment, file issues, and contribute on open-code features using the same GitHub workflows they’d normally use for our open-source features. Because we’ll maintain a clean directory structure and build processes between open-source and open-code bits, users can choose to build and use either licensed version.
What is the Timescale License (TSL)?
Up until now, everything released in our GitHub has been licensed under the Apache 2 open-source license. Today we are announcing that some upcoming features will be licensed under the new Timescale License (TSL).
Going forward, our GitHub repo will have both Apache 2 source code and TSL source code (but the latter isolated in a separate subdirectory). An open-source binary only includes Apache 2 code and is covered by the Apache 2 license, while a TSL binary includes both TSL and Apache 2 code and is covered by the Timescale License. All source code is open and public, and anybody can contribute. (But the TSL is not an open-source license, as per the definition by the OSI.)
This structure allows us to define three tiers of software features:
- Open-source features (free): Will continue to be licensed under the Apache 2 License. Going forward, we will continue investing in our open source core to add features and improve performance and usability.
- Community features (free): Will be licensed under the TSL, but will be made available at no charge. There are two exceptions that are prohibited from using these features (without a commercial agreement): (1) cloud and SaaS providers who just offer a hosted “database-as-a-service” version of TimescaleDB, and (2) OEMs that don’t provide any other value on top of the database. This tier enables us to continue to provide free features to and invest in our community, while protecting from open-source strip mining.
- Enterprise features (paid): Will require a paid relationship to use these features. In particular, a license key will be required to unlock these capabilities, even though no software upgrade or even restart will be required to upgrade from the Community tier. This tier enables us to generate revenue and become more self-sustaining.
For those interested in the nitty gritty of software licensing, you can find the new Timescale License in our GitHub repository.
Stay tuned for an upcoming release of our first community and enterprise features, which will include better data lifecycle management and automation through our new background scheduler framework. You can see their development all in the open, right in our public GitHub.
Explaining the nuances of the TSL
For those who’d like to learn more, we thought we’d spend a few more words explaining our motivations behind the nuances of the TSL.
In general, in our license we have attempted to clearly define the rights that are granted, and to protect users from accidentally violating the license. We’re not looking to be in the business of auditing companies for license compliance.
For example:
- By requiring a valid license key for using enterprise features, we explicitly protect users from accidentally using those features (and thus accidentally violating the license). Our users at larger companies, where it can be harder to monitor all TimescaleDB usage, have in particular asked for this kind of protection. Instead of providing accidental access to enterprise features, our license key checks will either raise warnings or refuse access, as appropriate.
- The TSL allows (and encourages) Value Added Products and Services, which we explicitly define by the interfaces to the database offered to end users. In other words, OEMs or SaaS providers can certainly allow their end users to query or write to the database (commonly known as DML operations), but the TSL prohibits them from allowing their end users to redefine or modify the underlying database structure or schema (e.g., through a DDL interface). Put another way, if someone were to offer both DML and DDL interfaces, they would effectively be providing a TimescaleDB database-as-a-service. We encourage you to reach out about your specific use case if you have questions.
Questions or feedback?
As mentioned above, we’ve made this decision carefully, soliciting feedback from our free users, paid customers, advisors, and other industry experts.
If anyone has any questions, we’re available. Please feel free to email us at licensing@timescale.com, or join the #timescale-license channel on our community Slack.
https://medium.com/media/70474f23bac1f5b27ed1e971c772238f/hrefHow we are building a self-sustaining open-source business in the cloud era was originally published in Timescale on Medium, where people are continuing the conversation by highlighting and responding to this story.
↧
↧
Luca Ferrari: PGVersion: a class to manage PostgreSQL Version (strings) within a Perl 6 Program
While writing a program in Perl 6 I had the need to correctly parse and analyze diffefent PostgreSQL version strings. I wrote a simple and minimal class to the aim, and refactored so it can escape in the wild.
PGVersion: a class to manage PostgreSQL Version (strings) within a Perl 6 Program
As you probably already know, PostgreSQL has changed its versioning number scheme from a major.major.minor approach to a concise major.minor one. Both are simple enought to be evaulated with a regular expression, but I found myself wrinting the same logic over and over, so I decided to write a minimal class to do the job for me and provide several information.
Oh, and this is Perl 6 (that I’m still learning!).
The class is named Fluca1978::Utils::PostgreSQL::PGVersion and is released as it is under the BSD Licence.
Quick, show me something!
Ok, here it is how it works:
useFluca1978::Utils::PostgreSQL::PGVersion;for<10.111beta111.19.6.56.11>{my$v=PGVersion.new::version-string($_);say"PostgreSQL version is $v";say"or for short { $v.gist }";say"and if you want a detailed version:\n{ $v.Str( True ) }";say"URL to download: { $v.http-download-url }";say'~~~~'x10;}The above simple loop provides the following output:
% perl6 -Ilib usage-example-pgversion.pl PostgreSQL version is v10.1 or for short 10.1 and if you want a detailed version: 10.1 (Major: 10,...↧
Ibrar Ahmed: Benchmark PostgreSQL With Linux HugePages

Linux kernel provides a wide range of configuration options that can affect performance. It’s all about getting the right configuration for your application and workload. Just like any other database, PostgreSQL relies on the Linux kernel to be optimally configured. Poorly configured parameters can result in poor performance. Therefore, it is important that you benchmark database performance after each tuning session to avoid performance degradation. In one of my previous posts, Tune Linux Kernel Parameters For PostgreSQL Optimization, I described some of the most useful Linux kernel parameters and how those may help you improve database performance. Now I am going to share my benchmark results with you after configuring Linux Huge Page with different PostgreSQL workload. I have performed a comprehensive set of benchmarks for many different PostgreSQL load sizes and different number concurrent clients.
Benchmark Machine
- Supermicro server:
- Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz
- 2 sockets / 28 cores / 56 threads
- Memory: 256GB of RAM
- Storage: SAMSUNG SM863 1.9TB Enterprise SSD
- Filesystem: ext4/xfs
- OS: Ubuntu 16.04.4, kernel 4.13.0-36-generic
- PostgreSQL: version 11
Linux Kernel Settings
I have used default kernel settings without any optimization/tuning except for disabling Transparent HugePages. Transparent HugePages are by default enabled, and allocate a page size that may not be recommended for database usage. For databases generally, fixed sized HugePages are needed, which Transparent HugePages do not provide. Hence, disabling this feature and defaulting to classic HugePages is always recommended.
PostgreSQL Settings
I have used consistent PostgreSQL settings for all the benchmarks in order to record different PostgreSQL workloads with different settings of Linux HugePages. Here is the PostgreSQL setting used for all benchmarks:
shared_buffers = '64GB' work_mem = '1GB' random_page_cost = '1' maintenance_work_mem = '2GB' synchronous_commit = 'on' seq_page_cost = '1' max_wal_size = '100GB' checkpoint_timeout = '10min' synchronous_commit = 'on' checkpoint_completion_target = '0.9' autovacuum_vacuum_scale_factor = '0.4' effective_cache_size = '200GB' min_wal_size = '1GB' wal_compression = 'ON'
Benchmark scheme
In the benchmark, the benchmark scheme plays an important role. All the benchmarks are run three times with thirty minutes duration for each run. I took the median value from these three benchmarks. The benchmarks were carried out using the PostgreSQL benchmarking tool pgbench. pgbench works on scale factor, with one scale factor being approximately 16MB of workload.
HugePages
Linux, by default, uses 4K memory pages along with HugePages. BSD has Super Pages, whereas Windows has Large Pages. PostgreSQL has support for HugePages (Linux) only. In cases where there is a high memory usage, smaller page sizes decrease performance. By setting up HugePages, you increase the dedicated memory for the application and therefore reduce the operational overhead that is incurred during allocation/swapping; i.e. you gain performance by using HugePages.
Here is the Hugepage setting when using Hugepage size of 1GB. You can always get this information from /proc.
AnonHugePages: 0 kB ShmemHugePages: 0 kB HugePages_Total: 100 HugePages_Free: 97 HugePages_Rsvd: 63 HugePages_Surp: 0 Hugepagesize: 1048576 kB
For more detail about HugePages please read my previous blog post.
https://www.percona.com/blog/2018/08/29/tune-linux-kernel-parameters-for-postgresql-optimization/
Generally, HugePages comes in sizes 2MB and 1GB, so it makes sense to use 1GB size instead of the much smaller 2MB size.
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/performance_tuning_guide/s-memory-transhuge
https://kerneltalks.com/services/what-is-huge-pages-in-linux/
Benchmark Results
This benchmark shows the overall impact of different sizes of HugePages. The first set of benchmarks was created with the default Linux 4K page size without enabling HugePages. Note that Transparent Hugepages were also disabled, and remained disabled throughout these benchmarks.
Then the second set of benchmarks was performed with 2MB HugePages. Finally, the third set of benchmarks is performed with HugePages set to 1GB in size.
All these benchmarks were executed with PostgreSQL version 11. The sets include a combination of different database sizes and clients. The graph below shows comparative performance results for these benchmarks with TPS (transactions per seconds) on the y-axis, and database size and the number of clients per database size on the x-axis.

Clearly, from the graph above, you can see that the performance gain with HugePages increases as the number of clients and the database size increases, as long as the size remains within the pre-allocated shared buffer.
This benchmark shows TPS versus clients. In this case, the database size is set to 48GB. On the y-axis, we have TPS and on the x-axis, we have the number of connected clients. The database size is small enough to fit in the shared buffer, which is set to 64GB.

With HugePages set to 1GB, the higher the number of clients, the higher the comparative performance gain.
The next graph is the same as the one above except for a database size of 96GB. This exceeds the shared buffer size, which is set to 64GB.

The key observation here is that the performance with 1GB HugePages improves as the number of clients increases and it eventually gives better performance than 2MB HugePages or the standard 4KB page size.
This benchmark shows the TPS versus database size. In this case, the number of connected clients it set to 32. On the y-axis, we have TPS and on the x-axis, we have database sizes.

As expected, when the database spills over the pre-allocated HugePages, the performance degrades significantly.
Summary
One of my key recommendations is that we must keep Transparent HugePages off. You will see the biggest performance gains when the database fits into the shared buffer with HugePages enabled. Deciding on the size of huge page to use requires a bit of trial and error, but this can potentially lead to a significant TPS gain where the database size is large but remains small enough to fit in the shared buffer.
↧
Michael Paquier: Postgres 12 highlight - wal_sender_timeout now user-settable
The following commit has reached PostgreSQL 12, which brings more flexibility in managing replication with standbys distributed geographically:
commit: db361db2fce7491303f49243f652c75c084f5a19
author: Michael Paquier <michael@paquier.xyz>
date: Sat, 22 Sep 2018 15:23:59 +0900
Make GUC wal_sender_timeout user-settable
Being able to use a value that can be changed on a connection basis is
useful with clusters distributed geographically, and makes failure
detection more flexible. A note is added in the documentation about the
use of "options" in primary_conninfo, which can be hard to grasp for
newcomers with the need of two single quotes when listing a set of
parameters.
Author: Tsunakawa Takayuki
Reviewed-by: Masahiko Sawada, Michael Paquier
Discussion: https://postgr.es/m/0A3221C70F24FB45833433255569204D1FAAD3AE@G01JPEXMBYT05
For some deployments, it matters to be able to change wal_sender_timeout depending on the standby and the latency with its primary (or another standby when dealing with a cascading instance). For example, a shorter timeout for a standby close to its primary allows faster problem detection and failover, while a longer timeout can become helpful for a standby in a remote location to judge correctly its health. In Postgres 11 and older versions, and this since wal_sender_timeout has been introduced since 9.1, this parameter can only be set at server-level, being marked as PGC_SIGHUP in its GUC properties. Changing the value of this parameter does not need an instance restart and the new value can be reloaded to all the sessions connected, including WAL senders.
The thread related to the above commit has also discussed if this parameter should be changed to be a backend-level parameter, which has the following properties:
- Reload does not work on it. Once this parameter is changed at connection time it can never change.
- Changing this parameter at server level will make all new connections using the new value.
- Role-level configuration is not possible.
Still, for default values, it is a huge advantage to be able to reload on-the-fly wal_sender_timeout depending on the state of an environment. So the choice has been made to make the parameter user-settable with PGC_USERSET so as it is possible to have values set up depending on the connected role (imagine different policies per role), and to allow the parameter to be reloaded for all sessions which do not enforce it at connection level. Coming back to the connection, the main advantage is that the value can be enforced using two different methods in primary_conninfo. First, and as mentioned previously, by connecting with a role which has a non-default value associated with it (this can be configured with ALTER ROLE). The second way is to pass directly the parameter “options” in a connection string, so as the following configuration gets used (single quotes are important!):
primary_conninfo = ' options=''-c wal_sender_timeout=60000'' ...'
Note as well that the SHOW command works across the replication protocol (since Postgres 10), so as it is possible to also check the effective value of a parameter at application level. Of course this is available for anything using the replication protocol, like a WAL archiver using pg_receivewal, logical workers, etc.
Making wal_sender_timeout configuration more flexible is extremely useful for many experienced users, so this is a great addition to Postgres 12.
↧
↧
Hans-Juergen Schoenig: A PostgreSQL story about “NULL IS NULL = NULL AND NOT NULL”
After years of software development, some might still wonder: What is a NULL value? What does it really mean and what is its purpose? The general rule is: NULL basically means “undefined”. Many books state that NULL means “empty” but I think that is not the ideal way to see things: If you wallet is empty, your financial situation is perfectly defined (= you are broke). But, “undefined” is different. It means that we don’t know the value. If we don’t know how much cash you got, you might still be a millionaire. So using the word “unknown” to describe NULL in SQL is really better than to use word “empty”, which can be pretty misleading in my judgement.
NULL values in PostgreSQL: Basic rules
First of all: NULL is a super useful thing in SQL and people should be aware of the details associated with it. Before digging deeper into NULL it is necessary to take a look at the most basic rules. The following example shows a mistake commonly made by many developers:
test=# SELECT 10 = NULL; ?column? ---------- (1 row)
Many people assume that the output of this query is actually “false”, which is not correct. The result is NULL. Why is that? Suppose you got 10 bucks in your left pocket and nobody knows how much cash you got in your right pocket. Is the amount of cash in your pockets the same? We don’t know. It might be very well so but we simply don’t know. Thus the result of this query has to be NULL.
Let us try something else:
test=# SELECT NULL = NULL; ?column? ---------- (1 row)
The same is true for this query. The result has to be NULL. We don’t know how much cash is in your left pocket and we got no idea how much there is in your right pocket. Is it identical? Again: We have absolutely no idea – the result is undefined.
To figure out if two values are actually NULL we have to use the following syntax:
test=# SELECT NULL IS NULL; ?column? ---------- t (1 row)
In this case the result is true because “IS” actually check if both value are indeed NULL. Consequently the next query is going to return false:
test=# SELECT 10 IS NULL; ?column? ---------- f (1 row)
However, there is more to NULL than just simple operations. NULL is key and therefore it is important to also check some of the lesser known aspects and corner cases.
row() and NULL handling
Some of my readers might already have seen the row() function, which can be used to form a tuple on the fly. In general pretty much the same rules will apply in this case. Consider the following example:
test=# SELECT row(NULL, NULL) = row(NULL, NULL); ?column? ---------- (1 row)
As expected the result is NULL because all values on both sides are “undefined” and therefore there is no way the output of this query can ever be true.
What is important to see is that a row can be compared to a single NULL value. In short: The entire tuple is considered to be NULL by PostgreSQL:
test=# SELECT row(NULL, NULL) IS NULL; ?column? ---------- t (1 row)
This is not true for row(10, NULL) – in this case the query returns false. True is only returned if all fields are NULL. However, there is one thing which might as a surprise to some people. The “IS” keyword won’t work if you are comparing the output of two “row” functions:
test=# SELECT row(NULL, NULL) IS row(NULL, NULL); ERROR: syntax error at or near "row" LINE 1: SELECT row(NULL, NULL) IS row(NULL, NULL);
PostgreSQL will immediately issue a syntax error.
NULL handling in LIMIT clauses
Some time ago I saw some people using NULL in LIMIT / OFFSET clauses. That is somewhat scary but still and interesting issue to think about. Consider the following example:
test=# CREATE TABLE demo (id int); CREATE TABLE test=# INSERT INTO demo VALUES (1), (2), (3); INSERT 0 3
The table simply contains 3 rows. Here is what LIMIT NULL does:
test=# SELECT * FROM demo LIMIT NULL; id ---- 1 2 3 (3 rows)
As you can see the entire resultset will be returned. That makes sense because PostgreSQL does not really know when to stop returning rows. Thus, the query is equivalent to “SELECT * FROM demo”. In PostgreSQL there is also an ANSI SQL compliant way to limit the result of a query: FETCH FIRST … ROWS ONLY” is the “proper” way to limit the result of a query. In PostgreSQL 11 “FETCH FIRST ROWS ONLY” will also accept NULL and behave the same way as LIMIT NULL. Here is an example:
test=# SELECT * FROM demo FETCH FIRST NULL ROWS ONLY; id ---- 1 2 3 (3 rows)
Mind that this was not always the case. Old versions of PostgreSQL did not accept a NULL value here.
NULL handling in ORDER BY clauses
NULL values are especially tricky if you want to sort data. Usually NULL values appear at the end of a sorted list. The following listing shows an example:
test=# INSERT INTO demo VALUES (NULL); INSERT 0 1 test=# SELECT * FROM demo ORDER BY id DESC; id ---- 3 2 1 (4 rows)
The point is: Suppose you want to sort products by price. The most expensive ones or most likely not the ones without a price. Therefore it is usually a good idea to out NULL values at the end of the list if you are ordering descendingly.
Here is how it works:
test=# SELECT * FROM demo ORDER BY id DESC NULLS LAST; id ---- 3 2 1 (4 rows)
Having the NULL values at the end is somewhat more intuitive and usually offers better user experience.
NULL and sum, count, avg, etc.
The way NULLs are handled are also important if you want to run a more analytical type of workload. In general rule is simple: Aggregate functions will simply ignore NULL values. The only exception to the rule is count(*). Here is an example:
test=# SELECT count(*), count(id) FROM demo;
count | count
-------+-------
4 | 3
(1 row)
count(*) will count ALL the rows – regardless of its content. count(column) will only count the not-NULL values inside a column, which is simply a different thing than just counting everything. Let us take a look at the next example:
test=# SELECT sum(id), avg(id) FROM demo; sum | avg -----+-------------------- 6 | 2.0000000000000000 (1 row)
As I have stated before: The aggregates do not count the NULL values, which means that the average of those 4 rows will be 2 and not 1.5.
The fact that count(*) counts all rows can create subtle bugs when used in an outer join. Consider the following example:
SELECT name, count(*)
FROM person AS a LEFT JOIN house AS b
ON a.id = b.person_id
GROUP BY name;
In this case every count will be at least 1 – even if the person in the list has no house. Keep in mind: The LEFT JOIN will add NULL values to the right side of the join. count(*) will count those NULL values and therefore even the poorest fellow will end up with at least one house. count(*) and outer joins are usually an alarm signal and should be handled with care.
The post A PostgreSQL story about “NULL IS NULL = NULL AND NOT NULL” appeared first on Cybertec.
↧
Bruce Momjian: Compiled PL/pgSQL?
PL/pgSQL has good alignment with SQL. When first executed in a session, the PL/pgSQL source is compiled to an abstract syntax tree which is then executed every time the PL/pgSQL function is executed in the session. Other languages have different compile behavior:
- PL/Perl compiles to bytecode on first call, similar to PL/pgSQL
- PL/Python loads pyc bytecode files
- SPI loads machine-language instruction files (object files)
This email thread covers some of the details. Keep in mind that most server-side functions spend the majority of their time running SQL queries, so the method of compilation is often insignificant.
↧
Avinash Kumar: Backup and Restore a PostgreSQL Cluster With Multiple Tablespaces Using pg_basebackup

![]() pg_basebackup is a widely used PostgreSQL backup tool that allows us to take an ONLINE and CONSISTENT file system level backup. These backups can be used for point-in-time-recovery or to set up a slave/standby. You may want to refer to our previous blog posts, PostgreSQL Backup Strategy, Streaming Replication in PostgreSQL and Faster PITR in PostgreSQL where we describe how we used pg_basebackup for different purposes. In this post, I’ll demonstrate the steps to restore a backup taken using pg_basebackup when we have many tablespaces that store databases or their underlying objects.
pg_basebackup is a widely used PostgreSQL backup tool that allows us to take an ONLINE and CONSISTENT file system level backup. These backups can be used for point-in-time-recovery or to set up a slave/standby. You may want to refer to our previous blog posts, PostgreSQL Backup Strategy, Streaming Replication in PostgreSQL and Faster PITR in PostgreSQL where we describe how we used pg_basebackup for different purposes. In this post, I’ll demonstrate the steps to restore a backup taken using pg_basebackup when we have many tablespaces that store databases or their underlying objects.
A simple backup can be taken using the following syntax.
Tar and Compressed Format $ pg_basebackup -h localhost -p 5432 -U postgres -D /backupdir/latest_backup -Ft -z -Xs -P Plain Format $ pg_basebackup -h localhost -p 5432 -U postgres -D /backupdir/latest_backup -Fp -Xs -P
Using a tar and compressed format is advantageous when you wish to use less disk space to backup and store all tablespaces, data directory and WAL segments, with everything in just one directory (target directory for backup).
Whereas a plain format stores a copy of the data directory as is, in the target directory. When you have one or more non-default tablespaces, tablespaces may be stored in a separate directory. This is usually the same as the original location, unless you use
--tablespace-mappingto modify the destination for storing the tablespaces backup.
PostgreSQL supports the concept of tablespaces. In simple words, a tablespace helps us maintain multiple locations to scatter databases or their objects. In this way, we can distribute the IO and balance the load across multiple disks.
To understand what happens when we backup a PostgreSQL cluster that contains multiple tablespaces, let’s consider the following example. We’ll take these steps:
- Create two tablespaces in an existing master-slave replication setup.
- Take a backup and see what is inside the backup directory.
- Restore the backup.
- Conclude our findings
Create 2 tablespaces and take a backup (tar format) using pg_basebackup
Step 1 :
I set up a replication cluster using PostgreSQL 11.2. You can refer to our blog post Streaming Replication in PostgreSQL to reproduce the same scenario. Here are the steps used to create two tablespaces:
$ sudo mkdir /data_pgbench $ sudo mkdir /data_pgtest $ psql -c "CREATE TABLESPACE data_pgbench LOCATION '/data_pgbench'" $ psql -c "CREATE TABLESPACE data_pgtest LOCATION '/data_pgtest'" $ psql -c "select oid, spcname, pg_tablespace_location(oid) from pg_tablespace" oid | spcname | pg_tablespace_location -------+--------------+------------------------ 1663 | pg_default | 1664 | pg_global | 16419 | data_pgbench | /data_pgbench 16420 | data_pgtest | /data_pgtest (4 rows)
Step 2 :
Now, I create two databases in two different tablespaces, using pgbench to create a few tables and load some data in them.
$ psql -c "CREATE DATABASE pgbench TABLESPACE data_pgbench" $ psql -c "CREATE DATABASE pgtest TABLESPACE data_pgtest" $ pgbench -i pgbench $ pgbench -i pgtest
In a master-slave setup built using streaming replication, you must ensure that the directories exist in the slave, before running a
"CREATE TABLESPACE ..."on the master. This is because, the same statements used to create a tablespace are shipped/applied to the slave through WALs – this is unavoidable. The slave crashes with the following message, when these directories do not exist:
2018-12-15 12:00:56.319 UTC [13121] LOG: consistent recovery state reached at 0/80000F8 2018-12-15 12:00:56.319 UTC [13119] LOG: database system is ready to accept read only connections 2018-12-15 12:00:56.327 UTC [13125] LOG: started streaming WAL from primary at 0/9000000 on timeline 1 2018-12-15 12:26:36.310 UTC [13121] FATAL: directory "/data_pgbench" does not exist 2018-12-15 12:26:36.310 UTC [13121] HINT: Create this directory for the tablespace before restarting the server. 2018-12-15 12:26:36.310 UTC [13121] CONTEXT: WAL redo at 0/9000448 for Tablespace/CREATE: 16417 "/data_pgbench" 2018-12-15 12:26:36.311 UTC [13119] LOG: startup process (PID 13121) exited with exit code 1 2018-12-15 12:26:36.311 UTC [13119] LOG: terminating any other active server processes 2018-12-15 12:26:36.314 UTC [13119] LOG: database system is shut down 2018-12-15 12:27:01.906 UTC [13147] LOG: database system was interrupted while in recovery at log time 2018-12-15 12:06:13 UTC 2018-12-15 12:27:01.906 UTC [13147] HINT: If this has occurred more than once some data might be corrupted and you might need to choose an earlier recovery target.
Step 3 :
Let’s now use pg_basebackup to take a backup. In this example, I use a tar format backup.
$ pg_basebackup -h localhost -p 5432 -U postgres -D /backup/latest_backup -Ft -z -Xs -P 94390/94390 kB (100%), 3/3 tablespaces
In the above log, you could see that there are three tablespaces that have been backed up: one default, and two newly created tablespaces. If we go back and check how the data in the two tablespaces are distributed to appropriate directories, we see that there are symbolic links created inside the pg_tblspc directory (within the data directory) for the oid’s of both tablespaces. These links are directed to the actual location of the tablespaces, we specified in Step 1.
$ ls -l $PGDATA/pg_tblspc total 0 lrwxrwxrwx. 1 postgres postgres 5 Dec 15 12:31 16419 -> /data_pgbench lrwxrwxrwx. 1 postgres postgres 6 Dec 15 12:31 16420 -> /data_pgtest
Step 4 :
Here are the contents inside the backup directory, that was generated through the backup taken in Step 3.
$ ls -l /backup/latest_backup total 8520 -rw-------. 1 postgres postgres 1791930 Dec 15 12:54 16419.tar.gz -rw-------. 1 postgres postgres 1791953 Dec 15 12:54 16420.tar.gz -rw-------. 1 postgres postgres 5113532 Dec 15 12:54 base.tar.gz -rw-------. 1 postgres postgres 17097 Dec 15 12:54 pg_wal.tar.gz
Tar Files :
16419.tar.gzand
16420.tar.gzare created as a backup for the two tablespaces. These are created with the same names as the OIDs of their respective tablespaces.
Let’s now take a look how we can restore this backup to completely different locations for data and tablespaces.
Restore a backup with multiple tablespaces
Step 1 :
In order to proceed further with the restore, let’s first extract the base.tar.gz file. This file contains some important files that help us to proceed further.
$ tar xzf /backup/latest_backup/base.tar.gz -C /pgdata $ ls -larth /pgdata total 76K drwx------. 2 postgres postgres 18 Dec 14 14:15 pg_xact -rw-------. 1 postgres postgres 3 Dec 14 14:15 PG_VERSION drwx------. 2 postgres postgres 6 Dec 14 14:15 pg_twophase drwx------. 2 postgres postgres 6 Dec 14 14:15 pg_subtrans drwx------. 2 postgres postgres 6 Dec 14 14:15 pg_snapshots drwx------. 2 postgres postgres 6 Dec 14 14:15 pg_serial drwx------. 4 postgres postgres 36 Dec 14 14:15 pg_multixact -rw-------. 1 postgres postgres 1.6K Dec 14 14:15 pg_ident.conf drwx------. 2 postgres postgres 6 Dec 14 14:15 pg_dynshmem drwx------. 2 postgres postgres 6 Dec 14 14:15 pg_commit_ts drwx------. 6 postgres postgres 54 Dec 14 14:18 base -rw-------. 1 postgres postgres 4.5K Dec 14 16:16 pg_hba.conf -rw-------. 1 postgres postgres 208 Dec 14 16:18 postgresql.auto.conf drwx------. 2 postgres postgres 6 Dec 14 16:18 pg_stat drwx------. 2 postgres postgres 58 Dec 15 00:00 log drwx------. 2 postgres postgres 6 Dec 15 12:54 pg_stat_tmp drwx------. 2 postgres postgres 6 Dec 15 12:54 pg_replslot drwx------. 4 postgres postgres 68 Dec 15 12:54 pg_logical -rw-------. 1 postgres postgres 224 Dec 15 12:54 backup_label drwx------. 3 postgres postgres 28 Dec 15 12:57 pg_wal drwx------. 2 postgres postgres 4.0K Dec 15 12:57 global drwx------. 2 postgres postgres 32 Dec 15 13:01 pg_tblspc -rw-------. 1 postgres postgres 55 Dec 15 13:01 tablespace_map -rw-------. 1 postgres postgres 24K Dec 15 13:04 postgresql.conf -rw-r--r--. 1 postgres postgres 64 Dec 15 13:07 recovery.conf -rw-------. 1 postgres postgres 44 Dec 15 13:07 postmaster.opts drwx------. 2 postgres postgres 18 Dec 15 13:07 pg_notify -rw-------. 1 postgres postgres 30 Dec 15 13:07 current_logfiles
Step 2 :
The files that we need to consider for our recovery are :
- backup_label
- tablespace_map
When you open the backup_label file, we see the start WAL location, backup start time, etc. These are some details that help us perform a point-in-time-recovery.
$ cat backup_label START WAL LOCATION: 0/B000028 (file 00000001000000000000000B) CHECKPOINT LOCATION: 0/B000060 BACKUP METHOD: streamed BACKUP FROM: master START TIME: 2018-12-15 12:54:10 UTC LABEL: pg_basebackup base backup START TIMELINE: 1
Now, let us see what is inside the
tablespace_mapfile.
$ cat tablespace_map 16419 /data_pgbench 16420 /data_pgtest
In the above log, you could see that there are two entries – one for each tablespace. This is a file that maps a tablespace (oid) to its location. When you start PostgreSQL after extracting the tablespace and WAL tar files, symbolic links are created automatically by postgres – inside the pg_tblspc directory for each tablespace – to the appropriate tablespace location, using the mapping done in this files.
Step 3 :
Now, in order to restore this backup in the same postgres server from where the backup was taken, you must remove the existing data in the original tablespace directories. This allows you to extract the tar files of each tablespaces to the appropriate tablespace locations.
The actual commands for extracting tablespaces from the backup in this case were the following:
$ tar xzf 16419.tar.gz -C /data_pgbench (Original tablespace location) $ tar xzf 16420.tar.gz -C /data_pgtest (Original tablespace location)
In a scenario where you want to restore the backup to the same machine from where the backup was originally taken, we must use different locations while extracting the data directory and tablespaces from the backup. In order to achieve that, tar files for individual tablespaces may be extracted to different directories than the original directories specified in
tablespace_mapfile, upon which we can modify the
tablespace_mapfile with the new tablespace locations. The next two steps should help you to see how this works.
Step 3a :
Create two different directories and extract the tablespaces to them.
$ tar xzf 16419.tar.gz -C /pgdata_pgbench (Different location for tablespace than original) $ tar xzf 16420.tar.gz -C /pgdata_pgtest (Different location for tablespace than original)
Step 3b :
Edit the
tablespace_mapfile with the new tablespace locations. Replace the original location of each tablespace with the new location, where we have extracted the tablespaces in the previous step. Here is how it appears after the edit.
$ cat tablespace_map 16419 /pgdata_pgbench 16420 /pgdata_pgtest
Step 4 :
Extract pg_wal.tar.gz from backup to pg_wal directory of the new data directory.
$ tar xzf pg_wal.tar.gz -C /pgdata/pg_wal
Step 5 :
Create
recovery.confto specify the time until when you wish to perform a point-in-time-recovery. Please refer to our previous blog post– Step 3, to understand recovery.conf for PITR in detail.
Step 6 :
Once all of the steps above are complete you can start PostgreSQL.
You should see the following files renamed after recovery.
backup_label --> backup_label.old tablespace_map --> tablespace_map.old recovery.conf --> recovery.done
To avoid the exercise of manually modifying the tablespace_map file, you can use
--tablespace-mapping. This is an option that works when you use a plain format backup, but not with tar. Let’s see why you may prefer a tar format when compared to plain.
Backup of PostgreSQL cluster with tablespaces using plain format
Consider the same scenario where you have a PostgreSQL cluster with two tablespaces. You might see the following error when you do not use
--tablespace-mapping.
$ pg_basebackup -h localhost -p 5432 -U postgres -D /backup/latest_backup -Fp -Xs -P -v pg_basebackup: initiating base backup, waiting for checkpoint to complete pg_basebackup: checkpoint completed pg_basebackup: write-ahead log start point: 0/22000028 on timeline 1 pg_basebackup: directory "/data_pgbench" exists but is not empty pg_basebackup: removing contents of data directory "/backup/latest_backup"
What the above error means is that the pg_basebackup is trying to store the tablespaces in the same location as the original tablespace directory. Here
/data_pgbenchis the location of tablespace :
data_pgbench.And, now, pg_basebackup is trying to store the tablespace backup in the same location. In order to overcome this error, you can apply tablespace mapping using the following syntax.
$ pg_basebackup -h localhost -p 5432 -U postgres -D /backup/latest_backup -T "/data_pgbench=/pgdata_pgbench" -T "/data_pgtest=/pgdata_pgtest" -Fp -Xs -P
-Tis used to specify the tablespace mapping.
-Tcan be replaced by
--tablespace-mapping.
The advantage of using -T (
--tablespace-mapping) is that the tablespaces are stored separately in the mapping directories. In this example with plain format backup, you must extract all the following three directories in order to restore/recover the database using backup.
- /backup/latest_backup
- /pgdata_pgtest
- /pgdata_pgbench
However, you do not need a
tablespace_mapfile in this scenario, as it is automatically taken care of by PostgreSQL.
If you take a backup in tar format, you see all the tar files for base, tablespaces and WAL segments stored in the same backup directory, and just this directory can be extracted for performing restore/recovery. However, you must manually extract the tablespaces and WAL segments to appropriate locations and edit the tablespace_map file, as discussed above.
—
Image based on Photos by Alan James Hendry on Unsplash and Tanner Boriack on Unsplash
↧
Pierre-Emmanuel André: Setup a PostgreSQL cluster with repmgr and pgbouncer
Setup a PostgreSQL cluster with repmgr and pgbouncer
Recently I had to setup a PostgreSQL cluster and one of the prerequisites was to use repmgr.
In this post, I will explain you the work I did and how to setup this kind of cluster.
↧
↧
Bruce Momjian: Why Use Multi-Master?
Multi-master replication sounds great when you first hear about it — identical data is stored on more than one server, and you can query any server. What's not to like? Well, there is actually quite a bit not to like, but it isn't obvious. The crux of the problem relates to the write nature of databases. If this was a web server farm serving static data, using multiple web servers to handle the load is easily accomplished. However, databases, because they are frequently modified, make multi-master configurations problematic.
For example, how do you want to handle a write to one of the database servers in a multi-master setup? Do you lock rows on the other servers before performing the write to make sure they don't make similar conflicting writes (synchronous), or do you tell them later and programmatically or administratively deal with write conflicts (asynchronous)? Locking remote rows before local writes can lead to terrible performance, and telling them later means your data is inconsistent and conflicts need to be resolved.
In practice, few people use synchronous multi-master setups — the slowdown is too dramatic, and the benefits of being able to write to multiple servers is minimal. Remember all the data still must be written to all the servers, so there is no write-scaling benefit. (Read load balancing can be accomplished with streaming replication and Pgpool-II.)
↧
Bruce Momjian: Threaded Postgres
This amazing work by Konstantin Knizhnik created some experimental numbers of the benefits of moving Postgres from process forking to threading. (Much slower CreateProcess is used on Windows.)
His proof-of-concept showed that you have to get near 100 simultaneous queries before you start to see benefits. A few conclusions from the thread are that threading Postgres would open up opportunities for much simpler optimizations, particularly in parallel query and perhaps a built-in connection pooler. The downside is that some server-side languages like PL/Perl and PL/Python have interpreters that cannot be loaded multiple times into the same executable, making them of limited use in a threaded database server. Languages like PL/Java, that are made to run multiple threads safely, would benefit from threaded Postgres.
↧
Kaarel Moppel: Unearthing some hidden PostgreSQL 11 gems
It’s been already a bit over a month since the last Postgres major version was released (and also the 1st minor update is out) so it’s not exactly fresh out of the oven…and as usual there has been already a barrage of articles on the most prominent features. Which is great, as I can save some keyboard strokes on those. But there are of course some other little gems that didn’t get any spotlight (by the way release notes are about 13 pages long so a lot of stuff!)…and now luckily had some “aluminum tube time” to have a second look on some more interesting/useful little features and improvements. So here my findings (somewhat logically grouped).
General
- Add column pg_stat_activity.backend_type
This makes it possible to report the “connected/active users” correctly as just a “count(*)” could lie due to the “parallel query” features added already 2 versions ago.
- Allow ALTER TABLE to add a column with a non-null default without doing a table rewrite
Adding new columns with DEFAULT values to large and active tables is a classical beginner mistake, basically halting operation. But no more – Postgres is now a lot more beginner-friendly!
Performance
- Fill the unused portion of force-switched WAL segment files with zeros for improved compressibility
My favourite low-hanging fruit from this release…and I wonder why it took so long. Why is it cool? Well, one can now set the “archive_timeout” so low that RPO-s from 1 second (lower values currently not allowed) are doable without a replica, with plain WAL-shipping. A great alternative for semi-important systems where losing a couple of last records is not so tragic.
- Improve performance of monotonically increasing index additions
Them most common use case for “serial” ID columns got a 30-50% boost!
- Allow bitmap scans to perform index-only scans when possible
Bitmap index scans (which are quite different from normal index scans) could get quite costly, so this is very good news.
- Add support for large pages on Windows
Mostly known as “huge pages”, this feature (at least on Linux) is quite recommended for machines with more than 128GB of RAM. Needs to be enabled on OS side also though.
Replication
- Exclude unlogged tables, temporary tables, and pg_internal.init files from streaming base backups
This could be quite a time-saver for huge Data Warehouse type of databases where “unlogged” is used quite often for “staging” tables.
- Allow checksums of heap pages to be verified during streaming base backup
And actually if checksums are enabled on the master this happens by default! Can be disabled by “–no-verify-checksums” flag…but you should not. And there was actually also a “sister”-feature added where pg_verify_checksums tool can now run on an offline cluster which could be useful in some cases.
- Replicate TRUNCATE activity when using logical replication
A huge one for LR users. Previously there were no good workarounds except creating a DML trigger to catch truncations on the publisher side and to error out.
Partioning / “sharding”
- Allow INSERT, UPDATE, and COPY on partitioned tables to properly route rows to foreign partitions
This is supported only by postgres_fdw foreign tables but a great addition when you’re doing “home-grown sharding”.
- Allow postgres_fdw to push down aggregates to foreign tables that are partitions
Again great if you’re doing sharding – less data fetched equals faster queries, especially when network is a bit laggy.
- Allow partition elimination during query execution
Previously, partition elimination only happened at planning time, meaning many joins and prepared queries could not use partition elimination and it resulted in some unnecessary scans.
Auxilliary tools
- Add an approximately Zipfian-distributed random generator to pgbench
Quite a nice feature at least for me personally as I’m a big fan and user of pgbench for quick performance gauging. The feature allows tests to be more close to real-life use cases where we typically have a cold/hot data scenario and active data stays generally more or less in shared buffers. To use the feature one needs to change the default test script though, there’s no flag.
- Allow the random seed to be set in pgbench
More repeatable test runs, yay! I’ve made use of it already for example here.
- Allow initdb to set group read access to the data directory
This is actually useful for 3rd party file-based backup software, such which previously needed “root” or “postgres” privileges, which are of course not good for the cluster’s operational security.
- Reduce the number of files copied by pg_rewind
Good news for HA-tools that use pg_rewind automatically (Patroni for example). Helps to quickly restore cluster redundancy.
- Allow extension pg_prewarm to restore the previous shared buffer contents on startup
The extension can now be used to automatically reduce the time of degraded performance that usually lasts for a couple of minutes after a restart. Shared buffers are then periodically (or only on shutdown) stored in files and fetched back into shared buffers after a (re)start by 2 background workers. For bigger shared buffers sizes you also want to make sure that the Postgres $DATADIR has enough disk space.
- Add psql command \gdesc to display the names and types of the columns in a query result
Well that was that. Please write to comments section if you found some other small but cool additions for version 11 
The post Unearthing some hidden PostgreSQL 11 gems appeared first on Cybertec.
↧
Claire Giordano: The perks of sharing your Citus open source stories
Most of us who work with open source like working with open source. You get to build on what’s already been built, and you get to focus on inventing new solutions to new problems instead of reinventing the wheel on each project. Plus you get to share your work publicly (which can improve the state of the art in the industry) and you get feedback from developers outside your company. Hiring managers give it a +1 too, since sharing your code will sometimes trigger outside interest in what you’re doing and can be a big boon for recruiting. After all “smart people like to hang out with smart people”.
Open source downloads make it easy to try out new software
One of the (countless) benefits of working with open source is that it’s so much easier to try things out. Even at four o’clock in the morning, when the rest of the world seems like they’re asleep. We’ve come a long way from the years when the only way to try out new software was to secure an enterprise “try & buy” license: through a salesperson, during business hours, and only after you were done playing an annoying game of phone tag.
Today, when you’re hunting for a new way to solve a problem and you want to try out a new technology, that ability to download open source packages and be up and running in minutes takes a lot of friction out of the process.
Sharing your stories about how & what you did contributes to the state of the art, too
And the transparency of the open source culture goes beyond the sharing of source code. Being transparent about both the good and the bad of working with open source can help to promote best practices as well as helps to make things better. Lots of you also share your stories about how you solved a problem, built a thing, or created an order of magnitude efficiency. Whether by conference talk, case study interview, or blog post, we love it when users and customers of the Citus database share their stories about what their challenges were and how they solved their problems.
A conference talk from Microsoft: Citus and Postgres together
So we were understandably jazzed when Principal Engineer Min Wei of Microsoft gave a talk at PostgresOpen SV a few months ago. In Min’s talk, he walked the audience through the architecture of how he uses Citus and Postgres to manage Windows device telemetry to support an executive decision dashboard. Min has built a 700 core Citus database cluster on Microsoft Azure that ingests and deletes 3TB of data per day and handles 500 TB of read IO every day (in fact, every row will get read 10s of times each day.)
We agree with Min when he says that, “Distributed Postgres will be the future for large scale machine learning.”
Lots of useful Citus database stories available online
This year we’ve had the privilege of talking to 12 Citus customers about how they’ve used the Citus database for their multi-tenant SaaS applications and their real-time analytics use cases and their time series workflows. Interviewing these CTOs and Engineering Leaders is one of the most fun parts of my work. And for those of you who are building applications that need the performance of a distributed database that is relational (and that is Postgres, more specifically), it can be useful to hear how another CTO or another data architect has solved their problems. Big thank you to these people (you know who you are), and yet another +1 for the sharing economy.
Do you have a Citus database story to share?
Talk about burying the lede. This section is the whole reason for this blog post.
We love it when Citus users and customers share the stories about how and why they use Citus. Like this Citus story on Hipmunk’s engineering blog, the travel search company at Concur. Or this post from Algolia on building real time analytics at scale with Citus.
If you use Citus (open source or our database as a service or our enterprise software) and you don’t have the cycles or the motivation to write your own blog post—not to worry, there is another way to share.
This post is your official invitation to Share Your Citus Story with the world.
The form is quick and easy and the objective straightforward: share your Citus story with us and we’ll feature you on the share-your-story page and/or on social media. What’s in it for you? In addition to the good feeling of giving back and helping to improve things, we’ll send you a {insert your favorite positive adjective here} Citus elicorn hoodie to say thank you.
Since it’s a new program, not enough people know about it yet, but over time word of mouth should do the trick. Whether on twitter or your own internal slack, please tell your friends who are using Citus that there’s an easy way to shine a light on what they’re doing (and to get an awesome hoodie in the process.)
↧
↧
Michael Paquier: ON COMMIT actions with inheritance and partitions
The following bug fix has been committed to the PostgreSQL code tree, addressing an issue visibly since ON COMMIT support for CREATE TABLE has been added back in commit ebb5318 from 2002:
commit: 319a8101804f3b62512fdce1a3af1c839344b593
author: Michael Paquier <michael@paquier.xyz>
date: Fri, 9 Nov 2018 10:03:22 +0900
Fix dependency handling of partitions and inheritance for ON COMMIT
This commit fixes a set of issues with ON COMMIT actions when used on
partitioned tables and tables with inheritance children:
- Applying ON COMMIT DROP on a partitioned table with partitions or on a
table with inheritance children caused a failure at commit time, with
complains about the children being already dropped as all relations are
dropped one at the same time.
- Applying ON COMMIT DELETE on a partition relying on a partitioned
table which uses ON COMMIT DROP would cause the partition truncation to
fail as the parent is removed first.
The solution to the first problem is to handle the removal of all the
dependencies in one go instead of dropping relations one-by-one, based
on a suggestion from Álvaro Herrera. So instead all the relation OIDs
to remove are gathered and then processed in one round of multiple
deletions.
The solution to the second problem is to reorder the actions, with
truncation happening first and relation drop done after. Even if it
means that a partition could be first truncated, then immediately
dropped if its partitioned table is dropped, this has the merit to keep
the code simple as there is no need to do existence checks on the
relations to drop.
Contrary to a manual TRUNCATE on a partitioned table, ON COMMIT DELETE
does not cascade to its partitions. The ON COMMIT action defined on
each partition gets the priority.
Author: Michael Paquier
Reviewed-by: Amit Langote, Álvaro Herrera, Robert Haas
Discussion: https://postgr.es/m/68f17907-ec98-1192-f99f-8011400517f5@lab.ntt.co.jp
Backpatch-through: 10
For beginners, ON COMMIT actions can be defined as part of CREATE TABLE on a temporary table to perform action during commits of transactions using it:
- The default, PRESERVE ROWS, does nothing on the relation.
- DELETE ROWS will perform a truncation of the relation.
- DROP will remove the temporary relation at commit.
Immediate consequences of those definitions is that creating a temporary table which uses DROP out of a transaction context immediately drops it:
=# CREATE TEMP TABLE temp_drop (a int) ON COMMIT DROP;
CREATE TABLE
=# \d temp_drop
Did not find any relation named "temp_drop".
Or inserting tuples out of a transaction into a relation which uses DELETE ROWS lets the relation empty:
=# CREATE TEMP TABLE temp_delete_rows (a int) ON COMMIT DELETE ROWS;
CREATE TABLE
=# INSERT INTO temp_delete_rows VALUES (1);
INSERT 0 1
=# TABLE temp_delete_rows;
a
---
(0 rows)
The bug fixed by the commit mentioned above involves the dependencies between partitions and inheritance trees for relations. First there are a couple of restrictions to be aware of when using partitions or inheritance trees which include temporary tables:
- Temporary partitions can be added to a partitioned table only if the partitioned table it is attaching to is temporary. This may be relaxed in future versions depending on the user interest.
- For inheritance trees, temporary child relations can inherit from the parent if it is either temporary or non-temporary. So if the child is not a temporary relation, its parent cannot be temporary.
Then some problems showed up when mixing ON COMMIT actions across multiple layers of inheritance or partitions as the code has for a long time been running the DROP actions on each relation individually and afterwards the truncation of each relation, which led to interesting behaviors at transaction commit time. Here is an example:
=# BEGIN;
BEGIN
=# CREATE TEMP TABLE temp_parent (a int) PARTITION BY LIST (a)
ON COMMIT DROP;
=# CREATE TEMP TABLE temp_child_2 PARTITION OF temp_parent
FOR VALUES IN (2) ON COMMIT DELETE ROWS;
CREATE TABLE
=# INSERT INTO temp_parent VALUES (2);
INSERT 0 1
=# TABLE temp_parent;
a
---
2
(1 row)
=# COMMIT;
ERROR: XX000: could not open relation with OID 16420
LOCATION: relation_open, heapam.c:1138
So what happens here is that the parent is removed, causing its partitions to go away, then the follow-up truncation on the child simply fails. Fixing this set of issues has required reordering a bit the code so as the relation removals and truncations happen consistently:
- The truncations happen first on all the relations where DELETE ROWS is defined.
- Relation removal happens afterwards, with all the relations dropped in one shot using Postgres dependency machinery.
This means that child relations may get truncated uselessly if the parent is dropped at the end, but that keeps the code logic simple. Another thing to be aware of is that this bug fix has only found its way down to Postgres 10, which has added as option PERFORM_DELETION_QUIETLY so as the cascading removal of the children does not cause noise NOTICE messages. As nobody has complained about this bug for 15 years, and partitions begin (introduced in v10) are just beginning to get used in applications that’s a limitation not worth worrying about. Note also that ON COMMIT actions are not inherited from the parent, so each action needs to be enforced and defined to each member, with the default being to preserve rows.
↧
Bruce Momjian: Zero Downtime Pg_upgrade
Pg_upgrade can upgrade a multi-terabyte system in 3-5 minutes using link mode. There are some things that can be done to make it faster — particularly, migration of analyze statistics from the old to new clusters.
However, even if pg_upgrade could perform an upgrade in zero time, would that be a zero-downtime upgrade? I am not sure, since my previous blog post explains that the work of switching clients from the old cluster to the new one seems to be downtime in the sense that running sessions are either terminated and restarted, or new connections must wait for old connections to complete. Multi-master replication seems to be unique in offering a way for new sessions to start on the new cluster while old sessions finish on the old cluster, but unfortunately it adds complexity.
↧
Brian Fehrle: PostgreSQL Replication for Disaster Recovery

With Disaster Recovery, we aim to set up systems to handle anything that could go wrong with our database. What happens if the database crashes? What if a developer accidently truncates a table? What if we find out some data was deleted last week but we didn’t notice it until today? These things happen, and having a solid plan and system in place will make the DBA look like a hero when everyone else’s hearts have already stopped when a disaster rears its ugly head.
Any database that has any sort of value should have a way to implement one or more Disaster Recovery options. PostgreSQL has a very solid replication system built in, and is flexible enough to be set up in many configurations to aid with Disaster Recovery, should anything go wrong. We’ll focus on scenarios like questioned above, how to set up our Disaster Recovery options, and the benefits of each solution.
High Availability
With streaming replication in PostgreSQL, High Availability is simple to set up and maintain. The goal is to provide a failover site that can be promoted to master if the main database goes down for any reason, such as hardware failure, software failure, or even network outage. Hosting a replica on another host is great, but hosting it in another data center is even better.
For specifics for setting up streaming replication, Severalnines has a detailed deep dive available here. The official PostgreSQL Streaming Replication Documentation has detailed information on the streaming replication protocol and how it all works.
A standard setup will look like this, a master database accepting read / write connections, with a replica database receiving all WAL activity in near real-time, replaying all data change activity locally.
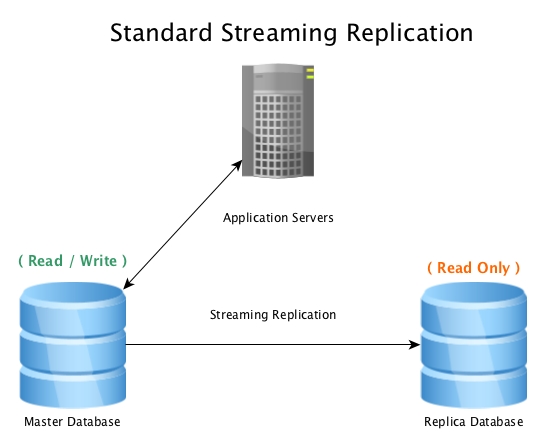
Standard Streaming Replication with PostgreSQL
When the master database becomes unusable, a failover procedure is initiated to bring it offline, and promote the replica database to master, then pointing all connections to the newly promoted host. This can be done by either reconfiguring a load balancer, application configuration, IP aliases, or other clever ways to redirect the traffic.
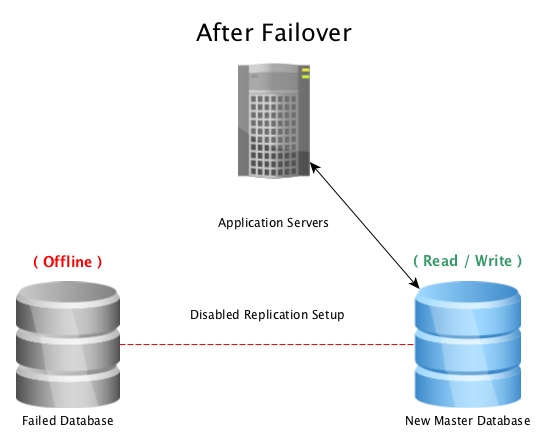
After a failover with PostgreSQL Streaming Replication
When disaster hits a master database (such as a hard drive failure, power outage, or anything that prevents the master from working as intended) , failing over to a hot standby is the quickest way to stay online serving queries to applications or customers without serious downtime. The race is then on to either fix the failed database host, or bring a new replica online to maintain the safety net of having a standby ready to go. Having multiple standbys will ensure that the window after a disastrous failure is also ready for a secondary failure, however unlikely it may seem.
Note: When failing over to a streaming replica, it will pick up where the previous master left off, so this helps with keeping the database online, but not recovering accidentally lost data.
Point In Time Recovery
Another Disaster Recovery option is Point in TIme Recovery (PITR). With PITR, a copy of the database can be brought back at any point in time we want, so long as we have a base backup from before that time, and all WAL segments needed up till that time.
A Point In Time Recovery option isn’t as quickly brought online as a Hot Standby, however the main benefit is being able to recover a database snapshot before a big event such as a deleted table, bad data being inserted, or even unexplainable data corruption. Anything that would destroy data in such a way where we would want to get a copy before that destruction, PITR saves the day.
Point in Time Recovery works by creating periodic snapshots of the database, usually by use of the program pg_basebackup, and keeping archived copies of all WAL files generated by the master
Point In Time Recovery Setup
Setup requires a few configuration options set on the master, some of which are good to go with default values on the current latest version, PostgreSQL 11. In this example, we’ll be copying the 16MB file directly to our remote PITR host using rsync, and compressing them on the other side with a cron job.
WAL Archiving
Master postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p postgres@pitrseveralnines:/mnt/db/wal_archive/%f'NOTE: The setting archive_command can be many things, the overall goal is to send all archived WAL files away to another host for safety purposes. If we lose any WAL files, PITR past the lost WAL file becomes impossible. Let your programming creativity go crazy, but make sure it’s reliable.
[Optional] Compress the archived WAL files:
Every setup will vary somewhat, but unless the database in question is very light in data updates, the buildup of 16MB files will fill up drive space fairly quickly. An easy compression script, set up through cron, could look like below.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]NOTE: During any recovery method, any compressed files will need to be decompressed later. Some administrators opt to only compress files after they are X number of days old, keeping overall space low, but also keeping more recent WAL files ready for recovery without extra work. Choose the best option for the databases in question to maximize your recovery speed.
Base Backups
One of the key components to a PITR backup is the base backup, and the frequency of base backups. These can be hourly, daily, weekly, monthly, but chose the best option based on recovery needs as well as the traffic of the database data churn. If we have weekly backups every Sunday, and we need to recover all the way to Saturday afternoon, then we bring the previous Sunday’s base backup online with all the WAL files between that backup and Saturday afternoon. If this recovery process takes 10 hours to process, this is likely undesirably too long, Daily base backups will reduce that recovery time, since the base backup would be from that morning, but also increase the amount of work on the host for the base backup itself.
If a week long recovery of WAL files takes just a few minutes, because the database sees low churn, then weekly backups are fine. The same data will exist in the end, but how fast you’re able to access it is the key.
In our example, we’ll set up a weekly base backup, and since we are using Streaming Replication for High Availability, as well as reducing the load on the master, we’ll be creating the base backup off of the replica database.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zNOTE: The pg_basebackup command assumes this host is set up for passwordless access for user ‘replication’ on the master, which can be done either by ‘trust’ in pg_hba for this PITR backup host, password in the .pgpass file, or other more secure ways. Keep security in mind when setting up backups.
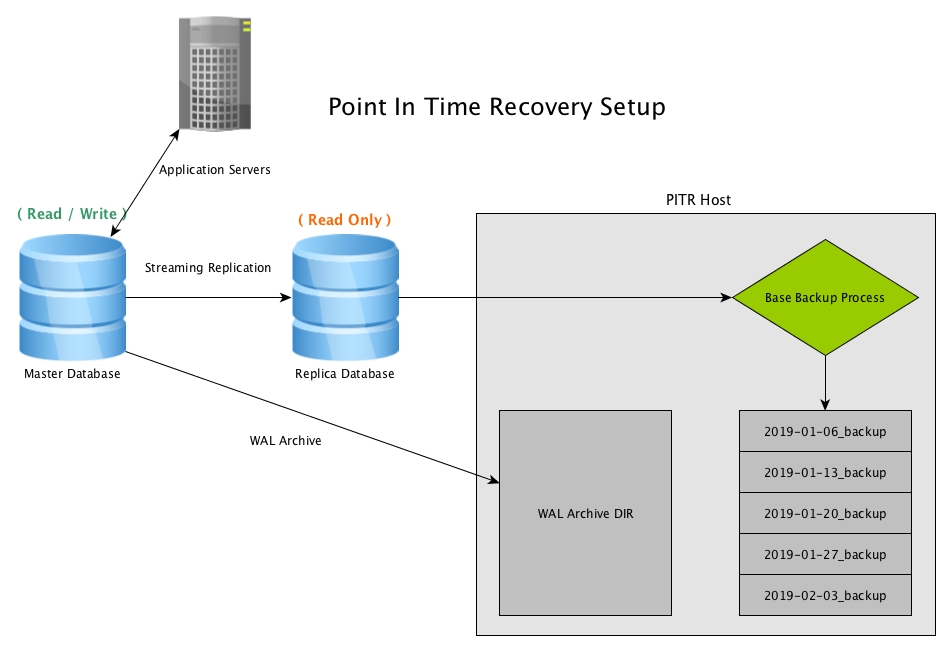
Point In Time Recovery (PITR) off a Streaming Replica with PostgreSQL
Download the Whitepaper Today
PostgreSQL Management & Automation with ClusterControl
Learn about what you need to know to deploy, monitor, manage and scale PostgreSQL
PITR Recovery Scenario
Setting up Point In Time Recovery is only part of the job, having to recover data is the other part. With good luck, this may never have to happen, however it’s highly suggested to periodically do a restoration of a PITR backup to validate that the system does work, and to make sure the process is known / scripted correctly.
In our test scenario, we’ll choose a point in time to recover to and initiate the recovery process. For example: Friday morning, a developer pushes a new code change to production without going through a code review, and it destroys a bunch of important customer data. Since our Hot Standby is always in sync with the master, failing over to it wouldn’t fix anything, as it would be the same data. PITR backups is what will save us.
The code push went in at 11 AM, so we need to restore the database to just before that time, 10:59 AM we decide, and luckily we do daily backups so we have a backup from midnight this morning. Since we don’t know what all was destroyed, we also decide to do a full restore of this database on our PITR host, and bring it online as the master, as it has the same hardware specifications as the master, just in case this scenario happened.
Shutdown The Master
Since we decided to restore fully from a backup and promote it to master, there’s no need to keep this online. We shut it down, but keep it around in case we need to grab anything from it later, just in case.
Set Up Base Backup For Recovery
Next, on our PITR host, we fetch our most recent base backup from before the event, which is backup ‘2018-12-21_backup’.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/With this, the base backup, as well as the WAL files provided by pg_basebackup are ready to go, if we bring it online now, it will recover to the point the backup took place, but we want to recover all of the WAL transactions between midnight and 11:59 AM, so we set up our recovery.conf file.
Create recovery.conf
Since this backup actually came from a streaming replica, there is likely already a recovery.conf file with replica settings. We will overwrite it with new settings. A detailed information list for all different options are available on PostgreSQL’s documentation here.
Being careful with the WAL files, the restore command will copy the compressed files it needs to the restore directory, uncompress them, then move to where PostgreSQL needs them for recovery. The original WAL files will remain where they are in case needed for any other reasons.
New recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Start The Recovery Process
Now that everything is set up, we will start the process for recovery. When this happens, it’s a good idea to tail the database log to make sure it’s restoring as intended.
Start the DB:
pg_ctl -D /var/lib/pgsql/11/data startTail the logs:
There will be many log entries showing the database is recovering from archive files, and at a certain point, it will show a line saying “recovery stopping before commit of transaction …”
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07At this point, the recovery process has ingested all WAL files, but is also in need of review before it comes online as a master. In this example, the log notes that the next transaction after the recovery target time of 11:59:00 was 11:59:01, and it was not recovered. To Verify, log in to the database and take a look, the running database should be a snapshot as of 11:59 exactly.
When everything looks good, time to promote the recovery as a master.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Now, the database is online, recovered to the point we decided, and accepting read / write connections as a master node. Ensure all configuration parameters are correct and ready for production.
The database is online, but the recovery process is not done yet! Now that this PITR backup is online as the master, a new standby and PITR setup should be set up, until then this new master may be online and serving applications, but it’s not safe from another disaster until that’s all set up again.
Other Point In Time Recovery Scenarios
Bringing back a PITR backup for a whole database is an extreme case, but there are other scenarios where only a subset of data is missing, corrupt, or bad. In these cases, we can get creative with our recovery options. Without bringing the master offline and replacing it with a backup, we can bring a PITR backup online to the exact time we want on another host (or another port if space isn’t an issue), and export the recovered data from the backup directly into the master database. This could be used to recover a handful of rows, a handful of tables, or any configuration of data needed.
With streaming replication and Point In Time Recovery, PostgreSQL gives us great flexibility on making sure we can recover any data we need, as long as we have standby hosts ready to go as a master, or backups ready to recover. A good Disaster Recovery option can be further expanded with other backup options, more replica nodes, multiple backup sites across different data centers and continents, periodic pg_dumps on another replica, etc.
These options can add up, but the real question is ‘how valuable is the data, and how much are you willing to spend to get it back?’. Many cases the loss of the data is the end of a business, so good Disaster Recovery options should be in place to prevent the worst from happening.
↧
Bruce Momjian: The Future of Major Version Upgrades
Pg_upgrade has matured to become a popular method to perform major version upgrades. This email thread considers what better upgrades would look like. Options include:
- Migrating analyze statistics
- Logical replication (requires double the disk space, managing schema changes)
- Multi-master replication (similar to previous, but also requires conflict resolution)
- Allowing the new server to read the old server's data files
Upgrade improvements have to be either significantly better in one of these measurements: faster, easier, more reliable, less required storage, and not significantly worse in any of those. For example, a solution that is 50% faster but is more complex or less reliable will be hard to gain acceptance. Of course, if a solution is one-hundred-times faster, it can be worse in some of those areas.
↧
↧
David Fetter: psql: A New Edit
Have you ever found yourself in the middle of a long statement in psql and wanted to pull up your favorite editor? Now, you can, using the same shortcut of control-x control-e that you would in bash!
Here's how:
Here's how:
$EDITOR ~/.inputrcNow add the following lines:
$if psql...save the file, and you're good to go.
"\C-x\C-e": "\C-e\\e\C-m"
$endif
↧
Avinash Kumar: Great things that happened with PostgreSQL in the Year 2018

In this blog post, we’ll look back at what’s been going on in the world of PostgreSQL in 2018.
Before we start talking about the good things that have happened in the PostgreSQL in 2018, we hope you had a wonderful year and we wish you a happy and prosperous 2019.
PostgreSQL has been a choice for those who are looking for a completely community-driven open source database that is feature-rich and extensible. We have seen tremendously great things happening in PostgreSQL for many years, with 2018 being a prime example. As you could see the following snippet from DB engine rankings, PostgreSQL has topped the chart for growth in popularity in the year 2018 compared to other databases.

PostgreSQL adoption growth has been increasing year over year, and 2018 has again been one such year as we can see.

Let’s start with a recap of some of the great PostgreSQL events, and look at what we should take away from 2018 in the PostgreSQL space.
PostgreSQL 11 Released
PostgreSQL 11 was a release that incorporated a lot of features offered in commercial database software governed by an enterprise license. For example, there are times when you are required to enforce the handling of embedded transactions inside a stored procedure in your application code. There are also times when you wish to partition a table with foreign keys or use hash partitioning. This used to require workarounds. The release of PostgreSQL 11 covers these scenarios.
There were many other add-ons as well, such as Just-In-Time compilation, improved query parallelism, partition elimination, etc. You can find out more in our blog post here, or the PostgreSQL 11 release notes (if you have not seen already). Special thanks to everyone involved in such a vibrant PostgreSQL release.
End of Life for PostgreSQL 9.3
9.3.25 was the last minor release that has happened for PostgreSQL 9.3 (on November 8, 2018). There will be no more minor releases supported by the community for 9.3. If you are still using PostgreSQL 9.3 (or a major earlier release than 9.3), it is the time to start planning to upgrade your database to take advantage of additional features and performance improvements.
Watch out for future Percona webinars (dates will be out soon) on PostgreSQL migrations and upgrades that will help handle situations such as downtime and other complexities involved in migrating your partitions built using table inheritance when you migrate from legacy PostgreSQL versions to the latest versions.
PostgreSQL Minor Releases
For minor PostgreSQL release, there was nothing new in what we saw this year compared to previous years. The PostgreSQL community aims for a minor version release for all the supported versions every quarter. However, we may see more minor releases due to critical bug fixes or security fixes. One of such release was done on March 3rd, 2018 for the CVE-2018-1058 security fix. This proves that you do not necessarily need to wait for specific release dates when a security vulnerability has been identified. You may see the fix released as a minor version as soon as the development, review and testing are completed for the fix.
There have been five minor releases this year on the following dates.
- 2018-11-08 (11.1, 10.6, 9.6.11, 9.5.15, 9.4.20, 9.3.25)
- 2018-08-09 (10.5, 9.6.10, 9.5.14, 9.4.19, 9.3.24)
- 2018-05-10 (10.4, 9.6.9, 9.5.13, 9.4.18, 9.3.23)
- 2018-03-01 (10.3, 9.6.8, 9.5.12, 9.4.17, 9.3.22)
- 2018-02-08 (10.2, 9.6.7, 9.5.11, 9.4.16, 9.3.21)
Security Fixes in All the Supported PostgreSQL Releases This Year
The PostgreSQL Global Development Team and contributors handle security fixes very seriously. There have been several instances where we have received immediate responses after reporting a problem or a bug. Likewise, we have seen many security bug fixes as soon as they have been reported.
Following are a list of security fixes we have seen in the year 2018:
We thank all the Core team, Contributors, Hackers and Users involved in making it another great year for PostgreSQL and a huge WIN for the open source world.
If you would like to participate in sharing your PostgreSQL knowledge to a wider audience, or if you have got a great topic that you would like to talk about, please submit your proposal to one of the world’s biggest open source conferences: Percona Live Open Source Database Conference 2019 in Austin, Texas from May 28-30, 2019. The Call for Papers is open until Jan 20, 2019.
You can also submit blog articles to our Open Source Database Community Blog for publishing to a wider open source database audience.
Please subscribe to our blog posts to hear many more great things that are happening in the PostgreSQL space.
↧
REGINA OBE: Using pg_upgrade to upgrade PostgreSQL 9.3 PostGIS 2.1 to PostgreSQL 11 2.5 on Yum
In a previous article Using pg upgrade to upgrade PostGIS without installing older version I demonstrated a trick for upgrading to a newer PostgreSQL instance from PostGIS 2.2 - 2.whatever without having to install the older version. Unfortunately that trick does not work if coming from PostGIS 2.1 because in PostGIS 2.2 we renamed a c lib function that backed sql functions in 2.1.
Fear not. There is still a way to upgrade from 2.1 to 2.5 without installing an older version of PostGIS in your new PostgreSQL instance. To do so, you need to add a step and that is to remove the functions in 2.1 that are backed by this renamed lib function. In upcoming PostGIS 3.0, we've added this function back and have it throw an error so that even coming from PostGIS 2.1, you can upgrade just the same as you do from later versions.
Continue reading "Using pg_upgrade to upgrade PostgreSQL 9.3 PostGIS 2.1 to PostgreSQL 11 2.5 on Yum"↧









