Parallel query support in PostgreSQL in the upcoming 9.6 release will be available for a number of query types: sequence scans, aggregates and joins. Because PostGIS tends to involve CPU-intensive calculations on geometries, support for parallel query has been at the top of our request list to the core team for a long time. Now that it is finally arriving the question is: does it really help?
TL;DR:
- With some adjustments to function
COSTboth parallel sequence scan and parallel aggregation deliver very good parallel performance results. - The cost adjustments for sequence scan and aggregate scan are not consistent in magnitude.
- Parallel join does not seem to work for PostGIS indexes yet, but perhaps there is some magic to learn from PostgreSQL core on that.
Setup
In order to run these tests yourself, you will need to check out and build:
- PostgreSQL 9.6 development code from the git master branch
- PostGIS 2.3 development code from this parallel enabled branch
For testing, I used the set of 69534polling divisions defined by Elections Canada.
shp2pgsql -s 3347 -I -D -W latin1 PD_A.shp pd | psql parallel
It’s worth noting that this data set is, in terms of number of rows very very small in database terms. This will become important as we explore the behaviour of the parallel processing, because the assumptions of the PostgreSQL developers about what constitutes a “parallelizable load” might not match our assumptions in the GIS world.
With the data loaded, we can do some tests on parallel query. Note that there are some new configuration options for parallel behaviour that will be useful during testing:
max_parallel_degreesets the maximum degree of parallelism for an individual parallel operation. Default 0.parallel_tuple_costsets the planner’s estimate of the cost of transferring a tuple from a parallel worker process to another process. The default is 0.1.parallel_setup_costsets the planner’s estimate of the cost of launching parallel worker processes. The default is 1000.force_parallel_modeallows the use of parallel queries for testing purposes even in cases where no performance benefit is expected. Default ‘off’.
Parallel Sequence Scan
Before we can test parallelism, we need to turn it on! The default max_parallel_degree is zero, so we need a non-zero value. For my tests, I’m using a 2-core laptop, so:
SETmax_parallel_degree=2;Now we are ready to run a query with a spatial filter. Using EXPLAIN ANALYZE suppressed the actual answer in favour of returning the query plan and the observed execution time:
EXPLAINANALYZESELECTCount(*)FROMpdWHEREST_Area(geom)>10000;And the answer we get back is:
Aggregate
(cost=14676.95..14676.97 rows=1 width=8)
(actual time=757.489..757.489 rows=1 loops=1)
-> Seq Scan on pd
(cost=0.00..14619.01 rows=23178 width=0)
(actual time=0.160..747.161 rows=62158 loops=1)
Filter: (st_area(geom) > '10000'::double precision)
Rows Removed by Filter: 7376
Planning time: 0.137 ms
Execution time: 757.553 ms
Two things we can learn here:
- There is no parallelism going on here, the query plan is just a single-threaded one.
- The single-threaded execution time is about 750ms.
Now we have a number of options to fix this problem:
- We can force parallelism using
SET force_parallel_mode=on, or - We can force parallelism by decreasing the
parallel_setup_cost, or - We can adjust the cost of
ST_Area()to try and get the planner to do the right thing automatically.
It turns out that the current definition of ST_Area() has a default COST setting, so it is considered to be no more or less expensive than something like addition or substraction. Since calculating area involves multiple floating point operations per polygon segment, that’s a stupid cost.
In general, all PostGIS functions are going to have to be reviewed and costed to work better with parallelism.
If we redefine ST_Area() with a big juicy cost, things might get better.
CREATEORREPLACEFUNCTIONST_Area(geometry)RETURNSFLOAT8AS'$libdir/postgis-2.3','area'LANGUAGE'c'IMMUTABLESTRICTPARALLELSAFECOST100;Now the query plan for our filter is much improved:
Finalize Aggregate
(cost=20482.97..20482.98 rows=1 width=8)
(actual time=345.855..345.856 rows=1 loops=1)
-> Gather
(cost=20482.65..20482.96 rows=3 width=8)
(actual time=345.674..345.846 rows=4 loops=1)
Number of Workers: 3
-> Partial Aggregate
(cost=19482.65..19482.66 rows=1 width=8)
(actual time=336.663..336.664 rows=1 loops=4)
-> Parallel Seq Scan on pd
(cost=0.00..19463.96 rows=7477 width=0)
(actual time=0.154..331.815 rows=15540 loops=4)
Filter: (st_area(geom) > '10000'::double precision)
Rows Removed by Filter: 1844
Planning time: 0.145 ms
Execution time: 349.345 ms
Three important things to note:
- We have a parallel query plan!
- Some of the execution results output are wrong! They say that only 1844 rows were removed by the filter, but in fact 7376 were (as we can confirm by running the queries without the
EXPLAIN ANALYZE). This is a known limitation, reporting on the results of only one parallel worker, which (should) maybe, hopefully be fixed before 9.6 comes out. - The execution time has been halved, just as we would hope for a 2-core machine!
Now for the disappointing part, try this:
EXPLAINANALYZESELECTST_Area(geom)FROMpd;Even though the work being carried out (run ST_Area() on 70K polygons) is exactly the same as in our first example, the planner does not parallelize it, because the work is not in the filter.
Seq Scan on pd
(cost=0.00..31654.84 rows=69534 width=8)
(actual time=0.130..722.286 rows=69534 loops=1)
Planning time: 0.078 ms
Execution time: 727.344 ms
For geospatial folks, who tend to do a fair amount of expensive calculation in the SELECT parameters, this is a bit disappointing. However, we still get impressive parallelism on the filter!
Parallel Aggregation
The aggregate most PostGIS users would like to see parallelized is ST_Union() so it’s worth explaining why that’s actually a little hard.
PostgreSQL Aggregates
All aggregate functions in PostgreSQL consist of at least two functions:
- A “transfer function” that takes in a value and a transfer state, and adds the value to the state. For example, the
Avg()aggregate has a transfer state consisting of the sum of all values seen so far, and the count of all values processed. - A “final function” that takes in a transfer state and converts it to the final aggregate output value. For example, the
Avg()aggregate final function divides the sum of all values by the count of all values and returns that number.
For parallel processing, PostgreSQL adds a third kind of function:
- A “combine” function, that takes in two transfer states and outputs a singe combined state. For the
Avg()aggregate, this would add the sums from each state and counts from each state and return that as the new combined state.
So, in order to get parallel processing in an aggregate, we need to define “combine functions” for all the aggregates we want parallelized. That way the master process can take the completed transfer states of all parallel workers, combine them, and then hand that final state to the final function for output.
To sum up, in parallel aggregation:
- Each worker runs “transfer functions” on the records it is responsible for, generating a partial “transfer state”.
- The master takes all those partial “transfer states” and “combines” them into a “final state”.
- The master then runs the “final function” on the “final state” to get the completed aggregate.
Note where the work occurs: the workers only run the transfer functions, and the master runs both the combine and final functions.
PostGIS ST_Union Aggregate
One of the things we are proud of in PostGIS is the performance of our ST_Union() implementation, which gains performance from the use of a cascaded union algorithm.
Cascaded union involves the following steps:
- Collects all the geometries of interest into an array (aggregate transfer function), then
- Builds a tree on those geometries and unions them from the leaves of the tree upwards (aggregate final function).
Note that all the hard work happens in the final step. The transfer functions (which is what would be run on the workers) do very little work, just gathering geometries into an array.
Converting this process into a parallel one by adding a combine function that does the union would not make things any faster, because the combine step also happens on the master. What we need is an approach that does more work during the transfer function step.
PostGIS ST_MemUnion Aggregate
“Fortunately” we have such an aggregate, the old union implementation from before we added “cascaded union”. The “memory friendly” union saves memory by not building up the array of geometries in memory, at the cost of spending lots of CPU unioning each input geometry into the transfer state.
In that respect, it is the perfect example to use for testing parallel aggregate.
The non-parallel definition of ST_MemUnion() is this:
CREATEAGGREGATEST_MemUnion(basetype=geometry,sfunc=ST_Union,stype=geometry);No special types or functions required: the transfer state is a geometry, and as each new value comes in the two-parameter version of the ST_Union() function is called to union it onto the state. There is no final function because the transfer state is the output value. Making the parallel version is as simple as adding a combine function that also uses ST_Union() to merge the partial states:
CREATEAGGREGATEST_MemUnion(basetype=geometry,sfunc=ST_Union,combinefunc=ST_Union,stype=geometry);Now we can run an aggregation using ST_MemUnion() to see the results. We will union the polling districts of just one riding, so 169 polygons:
EXPLAINANALYZESELECTST_Area(ST_MemUnion(geom))FROMpdWHEREfed_num=47005;Hm, no parallelism in the plan, and an execution time of 3.7 seconds:
Aggregate
(cost=14494.92..14495.18 rows=1 width=8)
(actual time=3784.781..3784.782 rows=1 loops=1)
-> Seq Scan on pd
(cost=0.00..14445.17 rows=199 width=2311)
(actual time=0.078..49.605 rows=169 loops=1)
Filter: (fed_num = 47005)
Rows Removed by Filter: 69365
Planning time: 0.207 ms
Execution time: 3784.997 ms
We have to bump the cost of the two parameter version of ST_Union() up to 10000 before parallelism kicks in:
CREATEORREPLACEFUNCTIONST_Union(geom1geometry,geom2geometry)RETURNSgeometryAS'$libdir/postgis-2.3','geomunion'LANGUAGE'c'IMMUTABLESTRICTPARALLELSAFECOST10000;Now we get a parallel execution! And the time drops down substantially, though not quite a 50% reduction.
Finalize Aggregate
(cost=16536.53..16536.79 rows=1 width=8)
(actual time=2263.638..2263.639 rows=1 loops=1)
-> Gather
(cost=16461.22..16461.53 rows=3 width=32)
(actual time=754.309..757.204 rows=4 loops=1)
Number of Workers: 3
-> Partial Aggregate
(cost=15461.22..15461.23 rows=1 width=32)
(actual time=676.738..676.739 rows=1 loops=4)
-> Parallel Seq Scan on pd
(cost=0.00..13856.38 rows=64 width=2311)
(actual time=3.009..27.321 rows=42 loops=4)
Filter: (fed_num = 47005)
Rows Removed by Filter: 17341
Planning time: 0.219 ms
Execution time: 2264.684 ms
The punchline though, is what happens when we run the query using a single-threaded ST_Union() with cascaded union:
EXPLAINANALYZESELECTST_Area(ST_Union(geom))FROMpdWHEREfed_num=47005;Good algorithms beat brute force still:
Aggregate
(cost=14445.67..14445.93 rows=1 width=8)
(actual time=2031.230..2031.231 rows=1 loops=1)
-> Seq Scan on pd
(cost=0.00..14445.17 rows=199 width=2311)
(actual time=0.124..66.835 rows=169 loops=1)
Filter: (fed_num = 47005)
Rows Removed by Filter: 69365
Planning time: 0.278 ms
Execution time: 2031.887 ms
The open question is, “can we combine the subtlety of the cascaded union algorithm with the brute force of parallel execution”?
Maybe, but it seems to involve magic numbers: if the transfer function paused every N rows (magic number) and used cascaded union to combine the geometries received thus far, it could possibly milk performance from both smart evaluation and multiple CPUs. The use of a magic number is concerning however, and the approach would be very sensitive to the order in which rows arrived at the transfer functions.
Parallel Join
To test parallel join, we’ll build a synthetic set of points, such that each point falls into one polling division polygon:
CREATETABLEptsASSELECTST_PointOnSurface(geom)::Geometry(point,3347)ASgeom,gid,fed_numFROMpd;CREATEINDEXpts_gixONptsUSINGGIST(geom);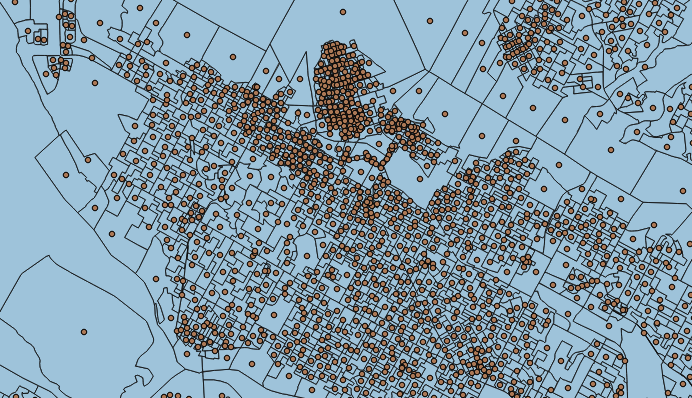
A simple join query looks like this:
EXPLAINANALYZESELECTCount(*)FROMpdJOINptsONST_Intersects(pd.geom,pts.geom);But the query plan has no parallel elements! Uh oh!
Aggregate
(cost=222468.56..222468.57 rows=1 width=8)
(actual time=13830.361..13830.362 rows=1 loops=1)
-> Nested Loop
(cost=0.28..169725.95 rows=21097041 width=0)
(actual time=0.703..13815.008 rows=69534 loops=1)
-> Seq Scan on pd
(cost=0.00..14271.34 rows=69534 width=2311)
(actual time=0.086..90.498 rows=69534 loops=1)
-> Index Scan using pts_gix on pts
(cost=0.28..2.22 rows=2 width=32)
(actual time=0.146..0.189 rows=1 loops=69534)
Index Cond: (pd.geom && geom)
Filter: _st_intersects(pd.geom, geom)
Rows Removed by Filter: 2
Planning time: 6.348 ms
Execution time: 13843.946 ms
The plan does involve a nested loop, so there should be an opportunity for parallel join to work magic. Unfortunately no variation of the query or the parallel configuration variables, or the function costs will change the situation: the query refuses to parallelize!
SETparallel_tuple_cost=0.001;SETforce_parallel_mode=on;SETparallel_setup_cost=1;The ST_Intersects() function is actually a SQL wrapper on top of the && operator and the _ST_Intersects() function, but unwrapping it and using the components directly also has no effect.
EXPLAINANALYZESELECTCount(*)FROMpdJOINptsONpd.geom&&pts.geomAND_ST_Intersects(pd.geom,pts.geom);The only variant I could get to parallelize omitted the && index operator.
EXPLAINSELECT*FROMpdJOINptsON_ST_Intersects(pd.geom,pts.geom);Unfortunately without the index operator the query is so inefficient it doesn’t matter that it’s being run in parallel, it will take days to run to completion.
Gather
(cost=1000.00..721919734.88 rows=1611658891 width=2552)
Number of Workers: 2
-> Nested Loop
(cost=0.00..576869434.69 rows=1611658891 width=2552)
Join Filter: _st_intersects(pd.geom, pts.geom)
-> Parallel Seq Scan on pd
(cost=0.00..13865.73 rows=28972 width=2512)
-> Seq Scan on pts
(cost=0.00..1275.34 rows=69534 width=40)
So, thus far, parallel query seems to be a wet squib for PostGIS, though I hope with some help from PostgreSQL core we can figure out where the problem lies.
Conclusions
While it is tempting to think “yay, parallelism! all my queries will run $ncores times faster!” in fact parallelism still only applies in a limited number of cases:
- When there is a sequence scan large (costly) enough to be worth parallelizing.
- When there is an aggregate large (costly) enough to be worth parallelizing, and the aggregate function can actually parallize the work effectively.
- (Theoretically) when there is a (nested loop) join large (costly) enough to be worth parallelizing.
Additionally there is still work to be done on PostGIS for optimal use of the parallel features we have available:
- Every function is going to need a cost, and those costs may have to be quite high to signal to the planner that we are not garden variety computations.
- Differences in
COSTadjustments for different modes need to be explored: why was a 10000 cost needed to kick the aggregation into action, while a 100 cost sufficed for sequence scan? - Aggregation functions that currently back-load work to the final function may have to be re-thought to do more work in the transfer stage.
- Whatever issue is preventing our joins from parallelizing needs to be tracked down.
All that being said, the potential is to see a large number of queries get $ncores faster, so this promises to be the most important core development we’ve seen since the extension framework arrived back in PostgreSQL 9.1.
 Today’s connected enterprise requires a single database that can handle both structured and unstructured data efficiently and that adapts dynamically to swiftly changing data changing and emerging data types. For many organizations, that database is Postgres. With JSON, Postgres can support document databases alongside relational tables and even combine structured and unstructured data.
Today’s connected enterprise requires a single database that can handle both structured and unstructured data efficiently and that adapts dynamically to swiftly changing data changing and emerging data types. For many organizations, that database is Postgres. With JSON, Postgres can support document databases alongside relational tables and even combine structured and unstructured data.