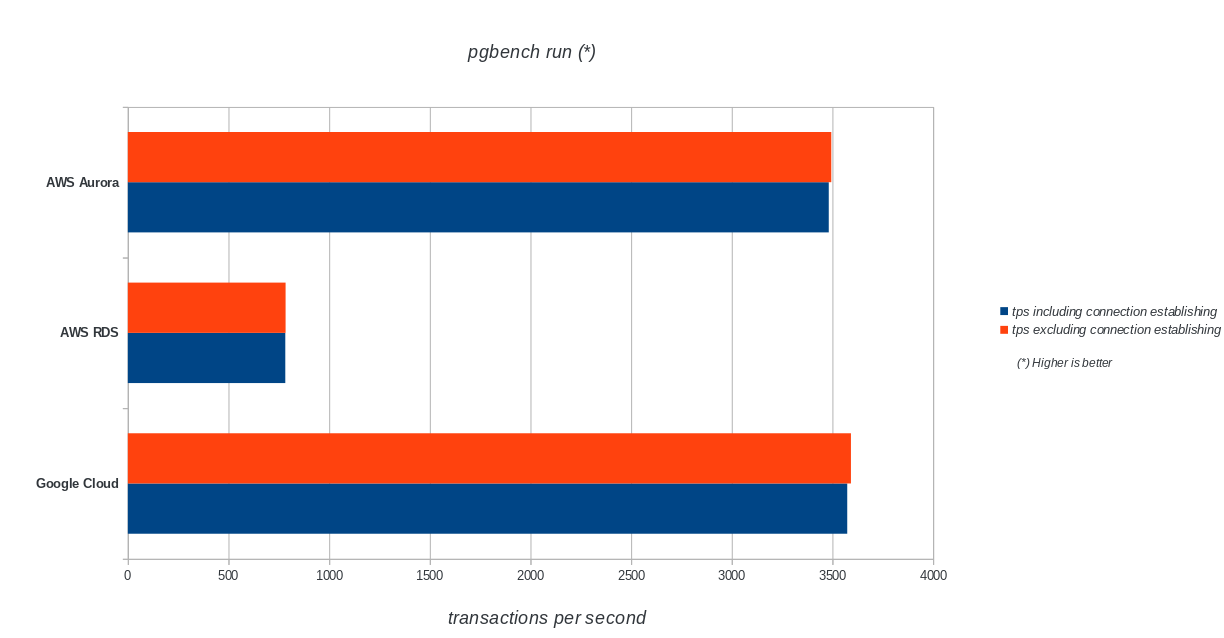
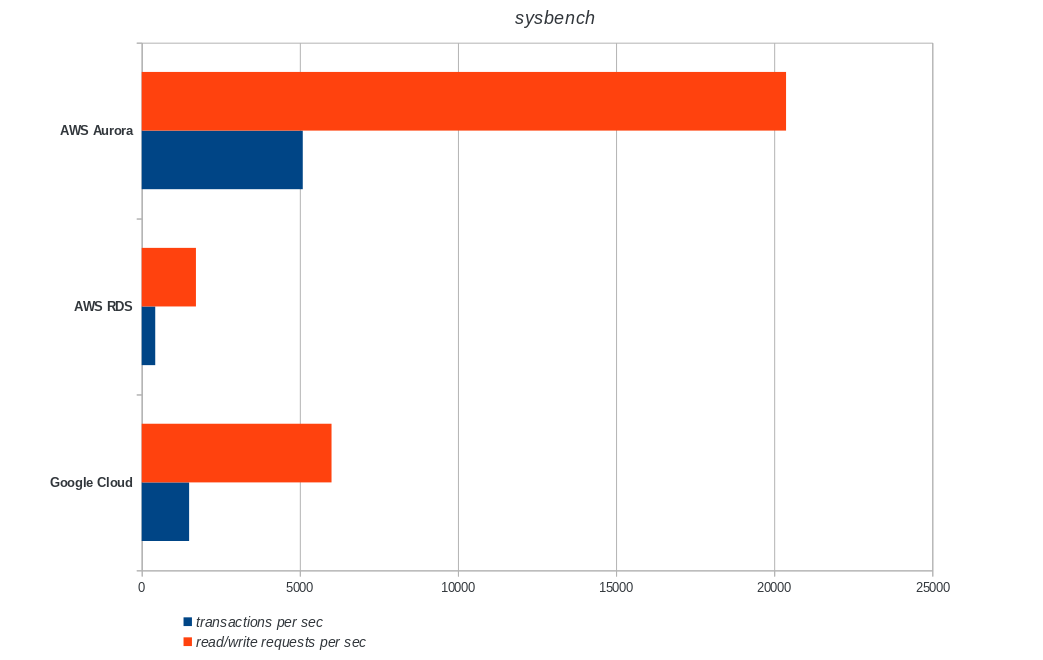
![]()
Database management systems are meant to house data but, occasionally, they may need to talk with another DBMS. For example, to access an external server which may be hosting a different DBMS. With heterogeneous environments becoming more and more common, a bridge between the servers is established. We call this bridge a “Foreign Data Wrapper” (FDW). PostgreSQL completed its support of SQL/MED (SQL Management of External Data) with release 9.3 in 2013. A foreign data wrapper is a shared library that is loaded by a PostgreSQL server. It enables the creation of foreign tables in PostgreSQL that act as proxies for another data source.
When you query a foreign table, Postgres passes the request to the associated foreign data wrapper. The FDW creates the connection and retrieves or updates the data in the external data store. Since PostgreSQL planner is involved in all of this process as well, it may perform certain operations like aggregate or joins on the data when retrieved from the data source. I cover some of these later in this post.
ClickHouse Database
ClickHouse is an open source column based database management system which claims to be 100–1,000x faster than traditional approaches, capable of processing of more than a billion rows in less than a second.
clickhousedb_fdw
clickhousedb_fdw is an open source project – GPLv2 licensed – from Percona. Here’s the link for GitHub project repository:
https://github.com/Percona-Lab/clickhousedb_fdw
It is an FDW for ClickHouse that allows you to SELECT from, and INSERT INTO, a ClickHouse database from within a PostgreSQL v11 server.
The FDW supports advanced features like aggregate pushdown and joins pushdown. These significantly improve performance by utilizing the remote server’s resources for these resource intensive operations.
If you would like to follow this post and try the FDW between Postgres and ClickHouse, you can download and set up the ontime dataset for ClickHouse. After following the instructions, the test that you have the desired data. The ClickHouse client is a client CLI for the ClickHouse Database.
Prepare Data for ClickHouse
Now the data is ready in ClickHouse, the next step is to set up PostgreSQL. We need to create a ClickHouse foreign server, user mapping, and foreign tables.
Install the clickhousedb_fdw extension
There are manual ways to install the clickhousedb_fdw, but clickhousedb_fdw uses PostgreSQL’s coolest extension install feature. By just entering a SQL command you can use the extension:
CREATE EXTENSION clickhousedb_fdw;
CREATE SERVER clickhouse_svr FOREIGN DATA WRAPPER clickhousedb_fdw OPTIONS(dbname 'test_database', driver '/use/lib/libclickhouseodbc.so');
CREATE USER MAPPING FOR CURRENT_USER SERVER clickhouse_svr;
CREATE FOREIGN TABLE clickhouse_tbl_ontime ( "Year" Int, "Quarter" Int8, "Month" Int8, "DayofMonth" Int8, "DayOfWeek" Int8, "FlightDate" Date, "UniqueCarrier" Varchar(7), "AirlineID" Int, "Carrier" Varchar(2), "TailNum" text, "FlightNum" text, "OriginAirportID" Int, "OriginAirportSeqID" Int, "OriginCityMarketID" Int, "Origin" Varchar(5), "OriginCityName" text, "OriginState" Varchar(2), "OriginStateFips" text, "OriginStateName" text, "OriginWac" Int, "DestAirportID" Int, "DestAirportSeqID" Int, "DestCityMarketID" Int, "Dest" Varchar(5), "DestCityName" text, "DestState" Varchar(2), "DestStateFips" text, "DestStateName" text, "DestWac" Int, "CRSDepTime" Int, "DepTime" Int, "DepDelay" Int, "DepDelayMinutes" Int, "DepDel15" Int, "DepartureDelayGroups" text, "DepTimeBlk" text, "TaxiOut" Int, "WheelsOff" Int, "WheelsOn" Int, "TaxiIn" Int, "CRSArrTime" Int, "ArrTime" Int, "ArrDelay" Int, "ArrDelayMinutes" Int, "ArrDel15" Int, "ArrivalDelayGroups" Int, "ArrTimeBlk" text, "Cancelled" Int8, "CancellationCode" Varchar(1), "Diverted" Int8, "CRSElapsedTime" Int, "ActualElapsedTime" Int, "AirTime" Int, "Flights" Int, "Distance" Int, "DistanceGroup" Int8, "CarrierDelay" Int, "WeatherDelay" Int, "NASDelay" Int, "SecurityDelay" Int, "LateAircraftDelay" Int, "FirstDepTime" text, "TotalAddGTime" text, "LongestAddGTime" text, "DivAirportLandings" text, "DivReachedDest" text, "DivActualElapsedTime" text, "DivArrDelay" text, "DivDistance" text, "Div1Airport" text, "Div1AirportID" Int, "Div1AirportSeqID" Int, "Div1WheelsOn" text, "Div1TotalGTime" text, "Div1LongestGTime" text, "Div1WheelsOff" text, "Div1TailNum" text, "Div2Airport" text, "Div2AirportID" Int, "Div2AirportSeqID" Int, "Div2WheelsOn" text, "Div2TotalGTime" text, "Div2LongestGTime" text,"Div2WheelsOff" text, "Div2TailNum" text, "Div3Airport" text, "Div3AirportID" Int, "Div3AirportSeqID" Int, "Div3WheelsOn" text, "Div3TotalGTime" text, "Div3LongestGTime" text, "Div3WheelsOff" text, "Div3TailNum" text, "Div4Airport" text, "Div4AirportID" Int, "Div4AirportSeqID" Int, "Div4WheelsOn" text, "Div4TotalGTime" text, "Div4LongestGTime" text, "Div4WheelsOff" text, "Div4TailNum" text, "Div5Airport" text, "Div5AirportID" Int, "Div5AirportSeqID" Int, "Div5WheelsOn" text, "Div5TotalGTime" text, "Div5LongestGTime" text, "Div5WheelsOff" text, "Div5TailNum" text) server clickhouse_svr options(table_name 'ontime');
postgres=# SELECT a."Year", c1/c2 as Value FROM ( select "Year", count(*)*1000 as c1
FROM clickhouse_tbl_ontime
WHERE "DepDelay">10 GROUP BY "Year") a
INNER JOIN (select "Year", count(*) as c2 from clickhouse_tbl_ontime
GROUP BY "Year" ) b on a."Year"=b."Year" LIMIT 3;
Year | value
------+------------
1987 | 199
1988 | 5202096000
1989 | 5041199000
(3 rows)Performance Features
PostgreSQL has improved foreign data wrapper processing by added the pushdown feature. Push down improves performance significantly, as the processing of data takes place earlier in the processing chain. Push down abilities include:
- Operator and function Pushdown
- Predicate Pushdown
- Aggregate Pushdown
- Join Pushdown
Operator and function Pushdown
The function and operators send to Clickhouse instead of calculating and filtering at the PostgreSQL end.
postgres=# EXPLAIN VERBOSE SELECT avg("DepDelay") FROM clickhouse_tbl_ontime WHERE "DepDelay" <10;
Foreign Scan (cost=1.00..-1.00 rows=1000 width=32) Output: (avg("DepDelay"))
Relations: Aggregate on (clickhouse_tbl_ontime)
Remote SQL: SELECT avg("DepDelay") FROM "default".ontime WHERE (("DepDelay" < 10))(4 rows)Predicate Pushdown
Instead of filtering the data at PostgreSQL, clickhousedb_fdw send the predicate to Clikhouse Database.
postgres=# EXPLAIN VERBOSE SELECT "Year" FROM clickhouse_tbl_ontime WHERE "Year"=1989;
Foreign Scan on public.clickhouse_tbl_ontime Output: "Year"
Remote SQL: SELECT "Year" FROM "default".ontime WHERE (("Year" = 1989)Aggregate Pushdown
Aggregate push down is a new feature of PostgreSQL FDW. There are currently very few foreign data wrappers that support aggregate push down – clickhousedb_fdw is one of them. Planner decides which aggregates are pushed down and which aren’t. Here is an example for both cases.
postgres=# EXPLAIN VERBOSE SELECT count(*) FROM clickhouse_tbl_ontime;
Foreign Scan (cost=1.00..-1.00 rows=1000 width=8)
Output: (count(*)) Relations: Aggregate on (clickhouse_tbl_ontime)
Remote SQL: SELECT count(*) FROM "default".ontimeJoin Pushdown
Again, this is a new feature in PostgreSQL FDW, and our clickhousedb_fdw also supports join push down. Here’s an example of that.
postgres=# EXPLAIN VERBOSE SELECT a."Year"
FROM clickhouse_tbl_ontime a
LEFT JOIN clickhouse_tbl_ontime b ON a."Year" = b."Year";
Foreign Scan (cost=1.00..-1.00 rows=1000 width=50);
Output: a."Year" Relations: (clickhouse_tbl_ontime a) LEFT JOIN (clickhouse_tbl_ontime b)
Remote SQL: SELECT r1."Year" FROM "default".ontime r1 ALL LEFT JOIN "default".ontime r2 ON (((r1."Year" = r2."Year")))Percona’s support for PostgreSQL
As part of our commitment to being unbiased champions of the open source database eco-system, Percona offers support for PostgreSQL – you can read more about that here. And as you can see, as part of our support commitment, we’re now developing our own open source PostgreSQL projects such as the clickhousedb_fdw. Subscribe to the blog to be amongst the first to know of PostgreSQL and other open source projects from Percona.
As an author of the new clickhousdb_fdw – as well as other FDWs – I’d be really happy to hear of your use cases and your experience of using this feature.
—
Photo by Hidde Rensink on Unsplash