Once you have finished the installation process of your PostgreSQL database server it is necessary to protect it before going into production. In this post, we will show you how to harden the security around your database to keep your data safe and secure.
1. Client Authentication Control
When installing PostgreSQL a file named pg_hba.conf is created in the database cluster's data directory. This file controls client authentication.
From the official postgresql documentation we can define the pg_hba.conf file as a set of records, one per line, where each record specifies a connection type, a client IP address range (if relevant for the connection type), a database name, a user name, and the authentication method to be used for connections matching these parameters.The first record with a matching connection type, client address, requested database, and user name is used to perform authentication.
So the general format will be something like this:
# TYPE DATABASE USER ADDRESS METHODAn example of configuration can be as follows:
# Allow any user from any host with IP address 192.168.93.x to connect
# to database "postgres" as the same user name that ident reports for
# the connection (typically the operating system user name).
#
# TYPE DATABASE USER ADDRESS METHOD
host postgres all 192.168.93.0/24 ident
# Reject any user from any host with IP address 192.168.94.x to connect
# to database "postgres
# TYPE DATABASE USER ADDRESS METHOD
host postgres all 192.168.94.0/24 rejectThere are a lot of combinations you can make to refine the rules (the official documentation describes each option in detail and has some great examples), but remember to avoid rules that are too permissive, such as allowing access for lines using DATABASE all or ADDRESS 0.0.0.0/0.
For ensuring security, even if you are forgetting to add a rule, you can add the following row at the bottom:
# TYPE DATABASE USER ADDRESS METHOD
host all all 0.0.0.0/0 rejectAs the file is read from top to bottom to find matching rules, in this way you ensure that for allowing permission you will need to explicitly add the matching rule above.
2. Server Configuration
There are some parameters on the postgresql.conf that we can modify to enhance security.
You can use the parameter listen_address to control which ips will be allowed to connect to the server. Here is a good practice to allow connections only from the known ips or your network, and avoid general values like “*”,”0.0.0.0:0” or “::”, which will tell PostgreSQL to accept connection from any IP.
Changing the port that postgresql will listen on (by default 5432) is also an option. You can do this by modifying the value of the port parameter.
Parameters such as work_mem, maintenance_work_mem, temp_buffer , max_prepared_transactions, temp_file_limit are important to keep in mind in case you have a denial of service attack. These are statement/session parameters that can be set at different levels (db, user, session), so managing these wisely can help us minimize the impact of the attack.
3. User and Role Management
The golden rule for security regarding user management is to grant users the minimum amount of access they need.
Managing this is not always easy and it can get really messy if not done well from the beginning.
A good way of keeping the privileges under control is to use the role, group, user strategy.
In postgresql everything is considered a role, but we are going to make some changes to this.
In this strategy you will create three different types or roles:
- role role (identified by prefix r_)
- group role (identified by prefix g_)
- user role (generally personal or application names)
The roles (r_ roles) will be the ones having the privileges over the objects. The group roles ( g_ roles ) will be granted with the r_ roles , so they will be a collection of r_ roles. And finally, the user roles will be granted with one or more group roles and will be the ones with the login privilege.
Let's show an example of this. We will create a read only group for the example_schema and then grant it to a user:
We create the read only role and grant the object privileges to it
CREATE ROLE r_example_ro NOSUPERUSER INHERIT NOCREATEDB NOCREATEROLE NOREPLICATION;
GRANT USAGE ON SCHEMA example to r_example_ro;
GRANT SELECT ON ALL TABLES IN SCHEMA example to r_example_ro;
ALTER DEFAULT PRIVILEGES IN SCHEMA example GRANT SELECT ON TABLES TO r_example_ro;We create the read only group and grant the role to that group
CREATE ROLE g_example_ro NOSUPERUSER INHERIT NOCREATEDB NOCREATEROLE NOREPLICATION';
GRANT r_example_ro to g_example_ro;We create the app_user role and make it "join" the read only group
CREATE ROLE app_user WITH LOGIN ;
ALTER ROLE app_user WITH PASSWORD 'somePassword' ;
ALTER ROLE app_user VALID UNTIL 'infinity' ;
GRANT g_example_ro TO app_user;Using this method you can manage the granularity of the privileges and you can easily grant and revoke groups of access to the users. Remember to only grant object privileges to the roles instead of doing it directly for the users and to grant the login privilege only to the users.
This is a good practice to explicitly revoke public privileges on the objects, like revoke the public access to a specific database and only grant it through a role.
REVOKE CONNECT ON my_database FROM PUBLIC;
GRANT CONNECT ON my_database TO r_example_ro;Restrict SUPERUSER access, allow superuser connections only from localhost/unix domain.
Use specific users for different purposes, like specific app users or backup users, and limit the connections for that user only from the required ips.
4. Super User Management
Maintaining a strong password policy is a must for keeping your databases safe and avoid the passwords hacks. For a strong policy use preferentially special characters, numbers, uppercase and lowercase characters and have at least 10 characters.
There are also external authentication tools, like LDAP or PAM, that can help you ensure your password expiration and reuse policy, and also handle account locking on authentication errors.
5. Data Encryption (on connection ssl)
PostgreSQL has native support for using SSL connections to encrypt client/server communications for increased security. SSL (Secure Sockets Layer) is the standard security technology for establishing an encrypted link between a web server and a browser. This link ensures that all data passed between the web server and browsers remain private and integral.
As postgresql clients sends queries in plain-text and data is also sent unencrypted, it is vulnerable to network spoofing.
You can enable SSL by setting the ssl parameter to on in postgresql.conf.
The server will listen for both normal and SSL connections on the same TCP port, and will negotiate with any connecting client on whether to use SSL. By default, this is at the client's option, but you have the option to setup the server to require use of SSL for some or all connections using the pg_hba config file described above.
6. Data Encryption at Rest (pg_crypto)
There are two basic kinds of encryption, one way and two way. In one way you don't ever care about decrypting the data into readable form, but you just want to verify the user knows what the underlying secret text is. This is normally used for passwords. In two way encryption, you want the ability to encrypt data as well as allow authorized users to decrypt it into a meaningful form. Data such as credit cards and SSNs would fall in this category.
For one way encryption, the crypt function packaged in pgcrypto provides an added level of security above the md5 way. The reason is that with md5, you can tell who has the same password because there is no salt (In cryptography, a salt is random data that is used as an additional input to a one-way function that "hashes" data, a password or passphrase), so all people with the same password will have the same encoded md5 string. With crypt, they will be different.
For data that you care about retrieving, you don't want to know if the two pieces of information are the same, but you don't know that information, and you want only authorized users to be able to retrieve it. Pgcrypto provides several ways of accomplishing this, so for further reading on how to use it you can check the oficial postgresql documentation on https://www.postgresql.org/docs/current/static/pgcrypto.html.
7. Logging
Postgresql provides a wide variety of config parameters for controlling what, when, and where to log.
You can enable session connection/disconnections, long running queries, temp file sizes and so on. This can help you get a better knowledge of your workload in order to identify odd behaviours. You can get all the options for logging on the following link https://www.postgresql.org/docs/9.6/static/runtime-config-logging.html
For more detailed information on your workload, you can enable the pg_stat_statements module, that provides a means for tracking execution statistics of all SQL statements executed by a server. There are some security tools that can ingest the data from this table and will generate an sql whitelist, in order to help you identify queries not following the expected patterns.
For more information https://www.postgresql.org/docs/9.6/static/pgstatstatements.html.
8. Auditing
The PostgreSQL Audit Extension (pgAudit) provides detailed session and/or object audit logging via the standard PostgreSQL logging facility.
Basic statement logging can be provided by the standard logging facility with log_statement = all. This is acceptable for monitoring and other usages but does not provide the level of detail generally required for an audit. It is not enough to have a list of all the operations performed against the database. It must also be possible to find particular statements that are of interest to an auditor. The standard logging facility shows what the user requested, while pgAudit focuses on the details of what happened while the database was satisfying the request.
9. Patching
Check PostgreSQL's security information page regularly and frequently for critical security updates and patches.
Keep in mind that OS or libraries security bugs can also lead to a database leak, so ensure you keeping the patching for these up to date.
ClusterControl provides an operational report that gives you this information and will execute the patches and upgrades for you.
10. Know Your Workload (pg_stats_statement)
In addition to the SQL-standard privilege system available through GRANT, tables can have row security policies that restrict, on a per-user basis, which rows can be returned by normal queries or inserted, updated, or deleted by data modification commands. This feature is also known as Row-Level Security.
When row security is enabled on a table all normal access to the table for selecting rows or modifying rows must be allowed by a row security policy.
Here is a simple example how to create a policy on the account relation to allow only members of the managers role to access rows, and only rows of their accounts:
CREATE TABLE accounts (manager text, company text, contact_email text);
ALTER TABLE accounts ENABLE ROW LEVEL SECURITY;
CREATE POLICY account_managers ON accounts TO managers USING (manager = current_user);You can get more information on this feature on the oficial postgresql documentation https://www.postgresql.org/docs/9.6/static/ddl-rowsecurity.html
If you would like to learn more, here are some resources that can help you to better strengthen your database security…
- https://www.postgresql.org/docs/9.6/static/auth-pg-hba-conf.html
- https://www.postgresql.org/docs/9.6/static/ssl-tcp.html
- https://www.postgresql.org/docs/current/static/pgcrypto.html
- http://www.postgresonline.com/journal/archives/165-Encrypting-data-with-pgcrypto.html
- https://github.com/pgaudit/pgaudit
- https://www.postgresql.org/docs/9.6/static/pgstatstatements.html
Conclusion
If you follow the tips above your server will be safer, but this does not mean that it will be unbreakable.
For your own security we recommend that you use a security test tool like Nessus, to know what your main vulnerabilities are and try to solve them.
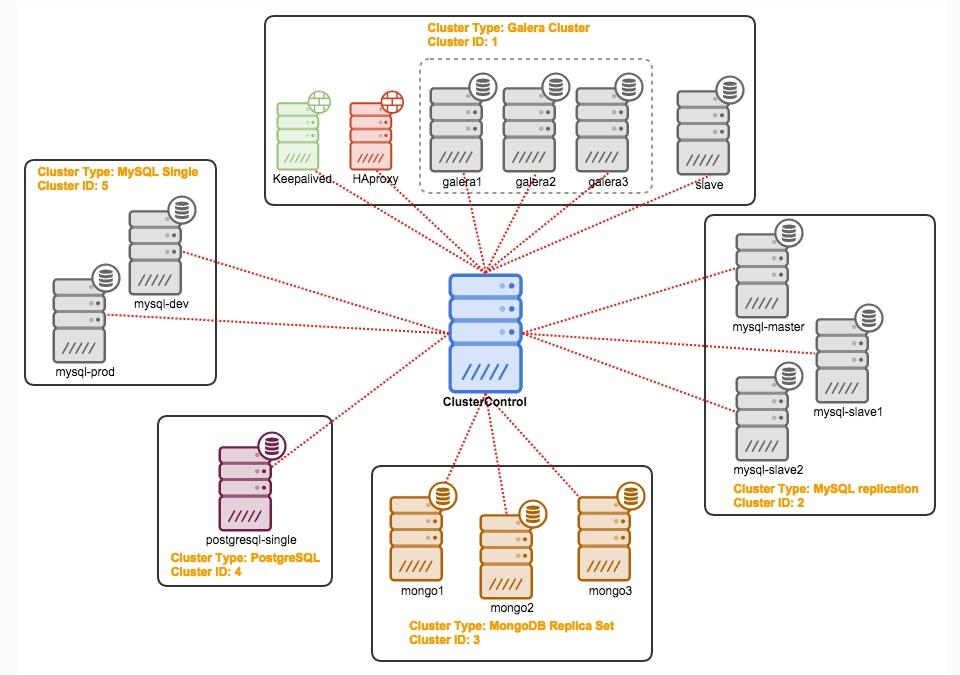
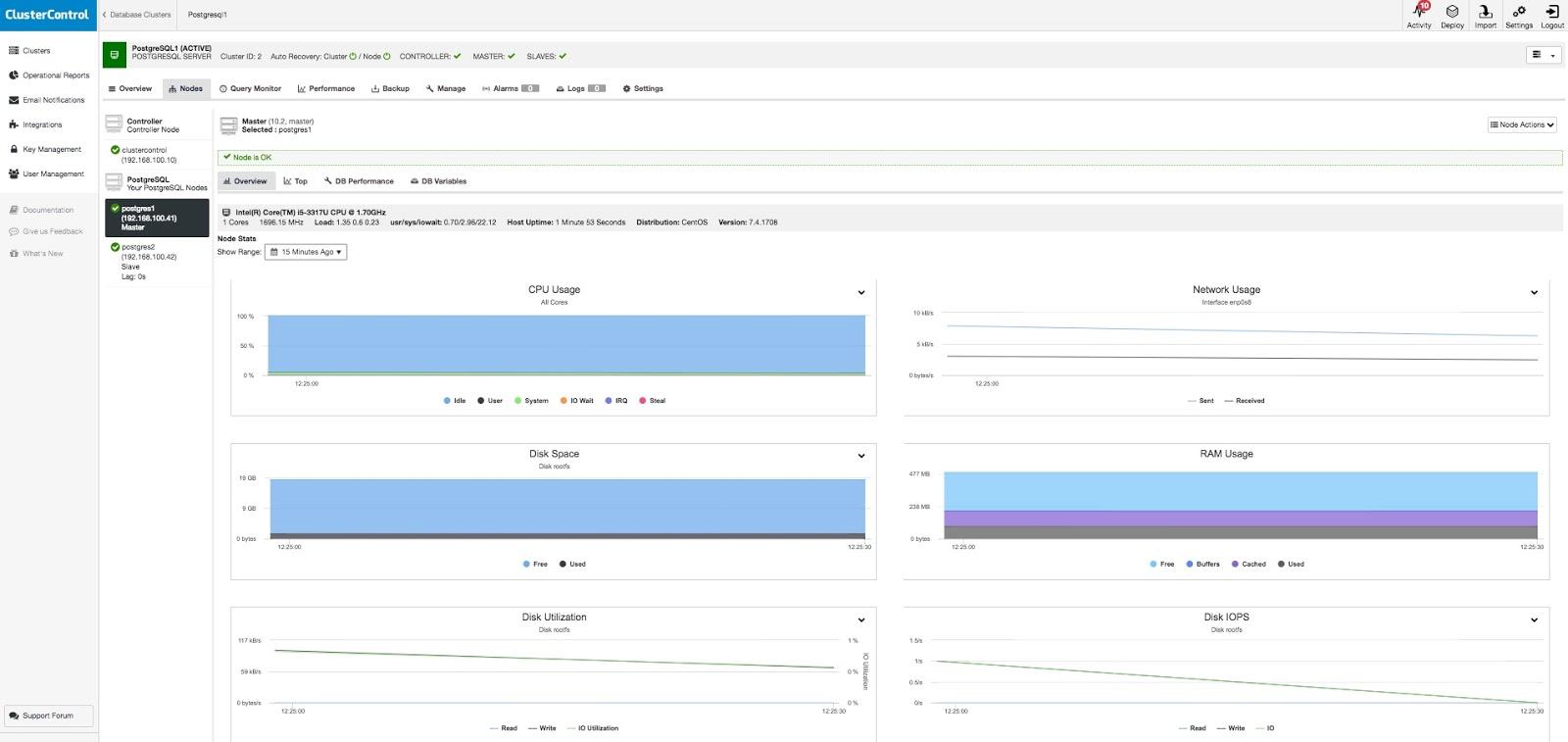
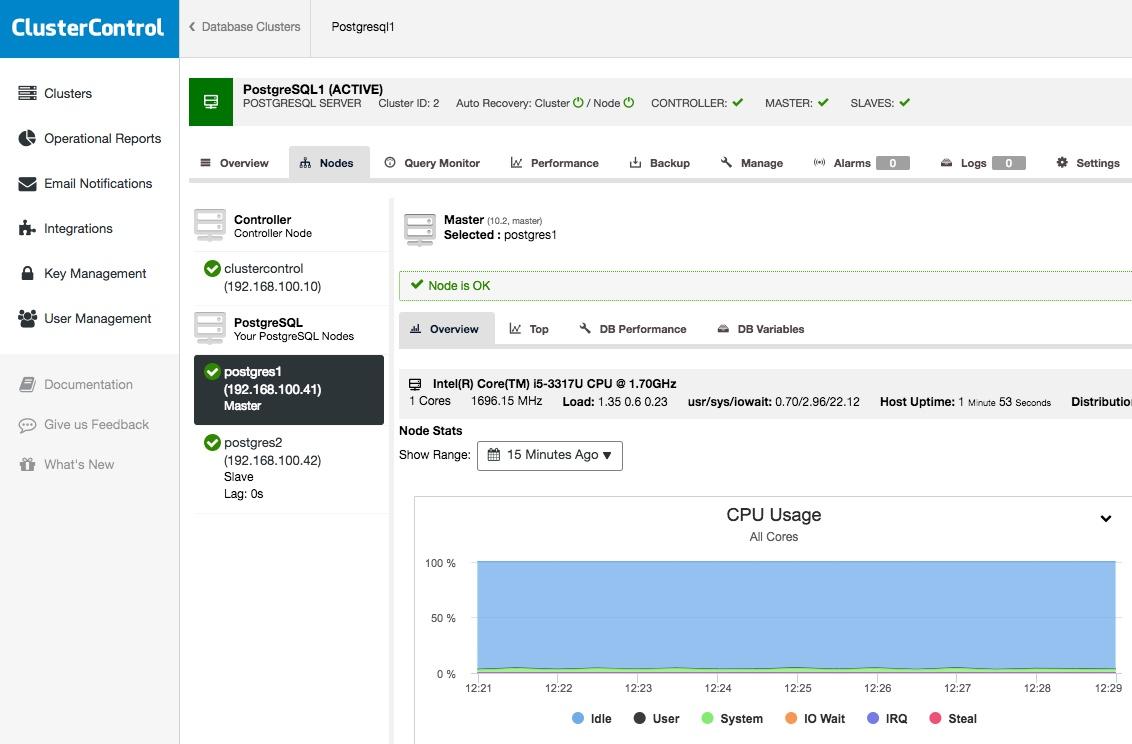
You can also monitor your database with ClusterControl. With this you can see in real time what's happening inside your database and analyze it.