Partitions in Postgres are a recent concept, being introduced as of version
10 and improved a lot over the last years. It is complicated, and doable,
to gather information about them with specific queries working on the system
catalogs, still these may not be straight-forward. For example, getting a
full partition tree leads to the
use of WITH RECURSIVE when working
on partitions with multiple layers.
Postgres 12 is coming with improvements in this regard with two commits.
The first one introduces a new system function to get easily information
about a full partition tree:
commit: d5eec4eefde70414c9929b32c411cb4f0900a2a9
author: Michael Paquier <michael@paquier.xyz>
date: Tue, 30 Oct 2018 10:25:06 +0900
Add pg_partition_tree to display information about partitions
This new function is useful to display a full tree of partitions with a
partitioned table given in output, and avoids the need of any complex
WITH RECURSIVE query when looking at partition trees which are
deep multiple levels.
It returns a set of records, one for each partition, containing the
partition's name, its immediate parent's name, a boolean value telling
if the relation is a leaf in the tree and an integer telling its level
in the partition tree with given table considered as root, beginning at
zero for the root, and incrementing by one each time the scan goes one
level down.
Author: Amit Langote
Reviewed-by: Jesper Pedersen, Michael Paquier, Robert Haas
Discussion: https://postgr.es/m/8d00e51a-9a51-ad02-d53e-ba6bf50b2e52@lab.ntt.co.jp
The second function is able to find the top-most parent of a partition
tree:
commit: 3677a0b26bb2f3f72d16dc7fa6f34c305badacce
author: Michael Paquier <michael@paquier.xyz>
date: Fri, 8 Feb 2019 08:56:14 +0900
Add pg_partition_root to display top-most parent of a partition tree
This is useful when looking at partition trees with multiple layers, and
combined with pg_partition_tree, it provides the possibility to show up
an entire tree by just knowing one member at any level.
Author: Michael Paquier
Reviewed-by: Álvaro Herrera, Amit Langote
Discussion: https://postgr.es/m/20181207014015.GP2407@paquier.xyz
First let’s take a set of partitions, working on two layers with an
index defined for all of them:
CREATE TABLE parent_tab (id int) PARTITION BY RANGE (id);
CREATE INDEX parent_index ON parent_tab (id);
CREATE TABLE child_0_10 PARTITION OF parent_tab
FOR VALUES FROM (0) TO (10);
CREATE TABLE child_10_20 PARTITION OF parent_tab
FOR VALUES FROM (10) TO (20);
CREATE TABLE child_20_30 PARTITION OF parent_tab
FOR VALUES FROM (20) TO (30);
INSERT INTO parent_tab VALUES (generate_series(0,29));
CREATE TABLE child_30_40 PARTITION OF parent_tab
FOR VALUES FROM (30) TO (40)
PARTITION BY RANGE(id);
CREATE TABLE child_30_35 PARTITION OF child_30_40
FOR VALUES FROM (30) TO (35);
CREATE TABLE child_35_40 PARTITION OF child_30_40
FOR VALUES FROM (35) TO (40);
INSERT INTO parent_tab VALUES (generate_series(30,39));
This set of partitioned tables with their partitions is really simple: one
parent with immediate children working on a range of values. Then one
of the children, child_30_40 has itself partitions, defined using a
subset of its own range. CREATE INDEX gets applied to all the partitions,
meaning that all these relations have a btree index on the column “id”.
First, pg_partition_tree() will display a full tree of it, taking
in input a relation used as base point for the parent of the tree,
so using parent_tab as input gives a complete tree:
=# SELECT * FROM pg_partition_tree('parent_tab');
relid | parentrelid | isleaf | level
-------------+-------------+--------+-------
parent_tab | null | f | 0
child_0_10 | parent_tab | t | 1
child_10_20 | parent_tab | t | 1
child_20_30 | parent_tab | t | 1
child_30_40 | parent_tab | f | 1
child_30_35 | child_30_40 | t | 2
child_35_40 | child_30_40 | t | 2
(7 rows)
And using one of the children gives the element itself if the relation
is a leaf partition, or can give a sub-tree:
=# SELECT * FROM pg_partition_tree('child_0_10');
relid | parentrelid | isleaf | level
------------+-------------+--------+-------
child_0_10 | parent_tab | t | 0
(1 row)
=# SELECT * FROM pg_partition_tree('child_30_40');
relid | parentrelid | isleaf | level
-------------+-------------+--------+-------
child_30_40 | parent_tab | f | 0
child_30_35 | child_30_40 | t | 1
child_35_40 | child_30_40 | t | 1
(3 rows)
Indexes part of partition trees are not at rest, and are handled
consistently as the relations they depend on:
=# SELECT * FROM pg_partition_tree('parent_index');
relid | parentrelid | isleaf | level
--------------------+--------------------+--------+-------
parent_index | null | f | 0
child_0_10_id_idx | parent_index | t | 1
child_10_20_id_idx | parent_index | t | 1
child_20_30_id_idx | parent_index | t | 1
child_30_40_id_idx | parent_index | f | 1
child_30_35_id_idx | child_30_40_id_idx | t | 2
child_35_40_id_idx | child_30_40_id_idx | t | 2
(7 rows)
The following fields show up:
relid is the OID, take it as relation name, for a given element
in the tree. This uses regclass as output to ease its use.
parentrelid refers to the immediate parent of the element.
isleaf will be true if the element does not have any partitions of
its own. In short it has physical storage.
level is a counter referring to the layer of the tree, beginning at
0 for the top-most parent, then incremented by 1 each time it moves
to the next layer.
When it comes to work with hundreds of partitions, this is first faster
than something going through all the catalog entries, like the specific
query using WITH RECURSIVE mentioned above (which could also be bundled
into an SQL function to provide the same results as the new in-core
functions introduced in this post). A second advantage is that it makes
aggregate operations much easier and readable. Getting the total
physical size covered by a given partition tree can be summarized by
that:
=# SELECT pg_size_pretty(sum(pg_relation_size(relid)))
AS total_partition_size
FROM pg_partition_tree('parent_tab');
total_partition_size
----------------------
40 kB
(1 row)
This works the same way for indexes, and switching to
pg_total_relation_size() would also give the total physical space
used for a given partition tree with all the full set of indexes
included.
The second function, pg_partition_root() becomes handy when it comes
to work with complicated partition trees. Depending on the application
policy where partitions are used, relation names can have structured
name policies, still from one version to another, and depending on the
addition of new features or logic layers, those policies can easily break,
leading to a mess first, and a hard time when it comes to figure out what
is actually the shape of the schema and the shape of a partition tree.
This function takes in input a relation name, and will return the top-most
parent of a partition tree:
Finally, with both combined, it is possible to get information about a
complete partition tree by just knowing one of its members:
=# SELECT * FROM pg_partition_tree(pg_partition_root('child_35_40'));
relid | parentrelid | isleaf | level
-------------+-------------+--------+-------
parent_tab | null | f | 0
child_0_10 | parent_tab | t | 1
child_10_20 | parent_tab | t | 1
child_20_30 | parent_tab | t | 1
child_30_40 | parent_tab | f | 1
child_30_35 | child_30_40 | t | 2
child_35_40 | child_30_40 | t | 2
(7 rows)
A last thing to note is that those functions return NULL if the input
refers to a relation kind which cannot be part of a partition tree, like
a view or a materialized view, and not an error. This makes easier the
creation of SQL queries doing for example scans of pg_class as there is
no need to create more WHERE filters based on the relation kind.
A PostgreSQL server may be accessible from the Internet, in the
sense that it may listen on a public IP address and a TCP port
accepting connections from any origin.
With the rising popularity of the DBaaS (“Database As A Service”) model,
database servers can be legitimately accessible from the Internet,
but it can also be the result of an unintentional misconfiguration.
As a data point, shodan.io, a scanner service that
monitors such things, finds currently more than
650,000 listening Postgres instances
on the Internet, without prejudging how they’re protected by
host-based access rules, strong passwords, and database-level grants.
Such an open configuration at the network level is opposed to the more
traditional, secure one where database servers are at least protected
by a firewall, or don’t even have a network interface connected to the
Internet, or don’t listen on it if they have one.
One consequence of having an instance listening to connections from
the Internet is that intrusion attempts on the default port 5432 may happen
anytime, just like it happens for other services such as ssh,
the mail system or popular web applications like Drupal, Wordpress
or phpMyAdmin.
If you have a server on the Internet, you may put its
IP address in the search field of shodan.io
to see what it knows about it.
The purpose of this post is to put together a few thoughts on this
topic, for people who already manage PostgreSQL instances accepting
public connections, or plan to do that in the future, or on the
contrary, want to make sure that their instances don’t do that.
Do not mistakenly open your instance to the Internet!
When asking “how to enable remote access to PostgreSQL?”, the typical answer is almost invariably to add some rules in pg_hba.conf and
set in postgresql.conf:
listen_addresses = *
(replacing the default listen_addresses = localhost).
It does work indeed, by making all the network interfaces to listen, but not
necessarily only those where these connections are expected. In the case
that they should come only from a private or
local network,
it’s safer to set only the addresses of the corresponding interfaces,
but that point is rarely made in public answers.
For instance, if the server is addressed as 192.168.1.12 in the
the local network, we could have instead:
listen_addresses = localhost, 192.168.1.12
Why use these addresses instead of * ? Or more generally: why hasn’t
PostgreSQL listen_addresses = *by default, so that a
remote host would connect right away, without requiring an
administrator to modify the configuration?
MongoDB used to do that, and the
scale of successful attacks against it somewhat illustrate why it’s not
a great idea. In 2015, shodan was reporting that about
30,000 instances
were accessible from anyone who cared to try, exposing 595 TB of data.
At the end of 2016, the “Mongo Lock” ransomware
started to impact a large fraction of these servers. The attack consisted
of deleting or encrypting data, replacing them with a demand for ransom
in bitcoins.
This episode has been a real setback for MongoDB’s reputation, even
though strictly speaking it was never a security hole but rather just an
insecure configuration.
The fact that installations were password-less by default played a big
role in the attacks, but the scale of the problem would have been much
less if the service has been listening only to its local network
address, as postgres does by default, since it’s sufficient in the
simple case when client and server-side are located on the same node.
Even though MongoDB has changed this default configuration a long time
ago (in 2014, in fact way before the more dire attacks),
it’s still being exploited currently, with incidents like
the leak of 200 million chinese CVs just last month (January 2019).
There are always installations out there that are left unmaintained,
or kept running by people unaware of their exposure, and that they
should change a configuration even though “it works”.
When an instance is purposefully open
Of course, database accounts must be protected by strong passwords,
but that’s not sufficient.
A pre-requisite is to stay informed on security updates and ready
to apply them urgently when necessary.
Such was the case in 2013, when the
CVE-2013-1899
vulnerability was announced: it allowed anyone with network access to
a PostgreSQL instance to compromise it, independently of the passwords
and rules in pg_hba.conf. That was pretty bad, and a concrete
example of why instances shouldn’t be exposed with listen_addresses
= * unless really necessary. As far as can be seen in public news
or user reports, it did not result in any campaign remotely comparable
to what happened with MongoDB.
The CVE-2013-1899 vulnerability seems tested by uninvited probes
still today, because when I’m looking to recent logs of my own
instance open to the outside, I can see entries like these:
2019-01-31 05:51:44 CET FATAL: no pg_hba.conf entry for host "185.x.x.x",
user "postgres", database "template0", SSL on
2019-01-31 05:51:44 CET FATAL: no pg_hba.conf entry for host "185.x.x.x",
user "postgres", database "template0", SSL off
2019-01-31 05:51:44 CET FATAL: unsupported frontend protocol 65363.19778: serve
r supports 1.0 to 3.0
2019-01-31 05:51:44 CET FATAL: no pg_hba.conf entry for host "185.x.x.x",
user "postgres", database "-h", SSL on
2019-01-31 05:51:44 CET FATAL: no pg_hba.conf entry for host "185.x.x.x",
user "postgres", database "-h", SSL off
-h as a database name is not choosen randomly, the above vulnerability
being described as:
Argument injection vulnerability in PostgreSQL 9.2.x before 9.2.4,
9.1.x before 9.1.9, and 9.0.x before 9.0.13 allows remote attackers to
cause a denial of service (file corruption), and allows remote
authenticated users to modify configuration settings and execute
arbitrary code, via a connection request using a database name that
begins with a “-“ (hyphen)
That kind of intrusion attempt can come from a service like shodan, or
from a botnet spreading
malware, or even an attacker that targets specifically this machine,
it’s hard to know.
The “Scarlett Johansson” cryptomining malware
There are some examples of successful attacks involving Postgres
to make it mine Monero.
As far as can be judged from outside, these attacks don’t exploit
any actual Postgres vulnerability, but succeed in connecting
as a superuser probably because of weak passwords, or mistakes
or laxism in pg_hba.conf, or by hacking first another
app or service having a privileged database access.
For instance in this question on dba.stackexchange:
Mysterious postgres process pegging CPU at 100%; no running queries, a user was asking why postgres was launching a ./Ac2p20853 command
using up all the CPU. The most plausible explanation was that the postgres account
or engine was compromised and this command was planted using postgres as a vector.
In short, once a superuser SQL session is obtained (by unspecified means),
the malware creates a SQL function able to execute any program on disk.
It creates such a program with lo_export() to download another
program that does the actual cryto-mining.
The program resided on a public image site, in this case hidden in a photo
of Scarlett Johansson, hence the unlikely reference to her in this
story.
Conclusion: superuser accounts should be limited to administration,
and whenever possible limited also to local connections, through
pg_hba.conf.
Forbid non-SSL remote connections
ssl=on in the server configuration implies that encryption is possible
when the client initiates it, but not that it’s mandatory.
Without encryption, an outsider with network access may read all data
between client and server, or even compromise it in transit.
If we want to force encryption from the point of view of the server,
this can be done through a set of rules in pg_hba.conf, such as
in the sample below. Remember that rules are interpreted in order of
appearance and that their evaluation stops as soon as a match is found, as
if it was an IF…ELSIF…ELSIF…END IF cascade).
# allow for "Unix domain sockets" password-less local connexions
# when OS user=db user
local all all peer
# allow for non-SSL locally, but with a password
host all all 127.0.0.1/32 md5 # or scram with PG 10 or newer
host all all ::1/128 md5
# reject non-encrypted remote connections
hostnossl all all 0.0.0.0/0 reject
hostnossl all all ::/0 reject
# add other rules starting here
...
...
The most common client library, libpq,
when compiled with SSL, tries by default an encrypted connection, followed by
a non-encrypted connection if the former fails. This behavior corresponds
to sslmode=prefer in the connection parameters (see SSL support in the documentation).
That’s why in the logs, an unsuccessful attempt to connect
appears as two entries, once with SSL=on and a second time with SSL=off.
Since version 9.5, it is possible to tell, among the established connections, which are encrypted and which are not, with the system view pg_stat_ssl:
Short of disallowing unencrypted sessions with pg_hba.conf, this query makes
it possible to check whether there are such connections and where they come from.
I worked with two companies this week to help them build open-source Postgres teams. Hopefully we will start seeing their activity in the community soon.
One tool I used to familiarize them with the Postgres community was PgLife. Written by me in 2013, PgLife presents a live dashboard of
all current Postgres activity, including user, developer, and external topics. Not only a dashboard, you can drill down into details too. All the titles on the left
are click-able, as are the detail items. The plus sign after each Postgres version shows the source code
changes since its release. Twitter and Slack references have recently been added.
I last mentioned PgLife here six years ago, so I thought I would mention it again. FYI, this is my
542nd blog entry. If you missed any of them, see my category index at the top of this page.
Extensions are capable of extending, changing, and advancing the behavior of Postgres. How? By hooking into low level Postgres API hooks. The open source Citus database that scales out Postgres horizontally is itself implemented as a PostgreSQL extension, which allows Citus to stay current with Postgres releases without lagging behind like other Postgres forks. I’ve previously written about the various types of extensions, today though I want to take a deeper look at the most useful Postgres extension: pg_stat_statements.
You see, I just got back from FOSDEM. FOSDEM is the annual free and open source software conference in Brussels, and at the event I gave a talk in the PostgreSQL devroom about Postgres extensions. By the end of the day, over half the talks that had been given in the Postgres devroom mentioned pg_stat_statements:
If you use Postgres and you haven’t yet used pg_stat_statements, it is a must to add it to your toolbox. And even if you are familiar, it may be worth a revisit.
Getting started with pg_stat_statements
Pg_stat_statements is what is known as a contrib extension, found in the contrib directory of a PostgreSQL distribution. This means it already ships with Postgres and you don’t have to go and build it from source or install packages. You may have to enable it for your database if it is not already enabled. This is as simple as:
CREATEEXTENSIONpg_stat_statements;
If you run on a major cloud provider there is a strong likelihood they have already installed and enabled it for you.
Once pg_stat_statements is installed, it begins silently going to work under the covers. Pg_stat_statements records queries that are run against your database, strips out a number of variables from them, and then saves data about the query, such as how long it took, as well as what happened to underlying reads/writes.
Note: It doesn’t save each individual query, rather it parameterizes them and then saves the aggregated result
Let’s look at how would work with a couple of examples. Suppose we execute the following query:
If this were a query in my application that I was frequently executing to get the order details for something like a retail order history, it wouldn’t save how often I ran this for each user, but rather for an aggregated view.
Looking at the data
From here we can query the raw data of pg_stat_statements and we’ll see something like:
Now there is a wealth of valuable information here, and as a more advanced user there are times where it can all prove valuable. But even without starting to understand the internals of your database, you can get some really powerful insights by querying pg_stat_statements in certain ways. By looking at the total_time and number of times a query is called per query, we can get a really quick view of which queries are very frequently run, as well as what they consume on average:
There are a number of different ways you can filter this and sort this, you may want to focus only on queries that are run over 1,000 times. Or queries that average over 100 milliseconds. The above query shows us the total amount of time in minutes that have been consumed against our database as well as the average time in milliseconds. With the above query I would get back something looks like:
As a rule of thumb, I know that when quickly grabbing a record, PostgreSQL should be able to return in 1ms. Given this I could get to work optimizing. On the above I see that bringing the first query down to 1ms would be an improvement, but optimizing the second query would give an even bigger boost in performance to my system overall.
A special note: If you’re building multi-tenant apps, you may not want pg_stat_statements to parameterize your tenant_id. To help with this, we built citus_stat_statements to give you per tenant insights.
If you haven’t looked at your data from pg_stat_statements ever—or even in the past month—today is a good day for it. What does it tell you about places you can optimize? We’d love to hear what you discover @citusdata.
PostgreSQL has two autovacuum-age related settings, autovacuum_freeze_max_age, and vacuum_freeze_table_age.
Both of them are in terms of the transaction “age” of a table: That is, how long it has been since the table has been scanned completely for “old” tuples that can be marked as “frozen” (a “frozen” tuple is one that no open transaction can cause to disappear by a rollback). In short, the “oldest” a table can become in PostgreSQL is 2^31-1 transactions; if a table were ever to reach that, data loss would occur. PostgreSQL takes great pains to prevent you from eaching that point.
The “vacuum freeze” process is the process that scans the table and marks these tuples as frozen.
vacuum_freeze_table_age causes a regular autovacuum run to be an “autovacuum (to prevent xid wraparound)” run, that is, an (auto)vacuum freeze, if the age of the table is higher than vacuum_freeze_table_age.
autovacuum_freeze_max_age will cause PostgreSQL to start an “autovacuum (to prevent xid wraparound)” run even if it has no other reason to vacuum the table, should a table age exceed that setting.
By default, vacuum_freeze_table_age = 100000000 (one hundred million), and autovacuum_freeze_max_age = 200000000 (two hundred million).
Do not change them.
In the past, I made a recommendation I now deeply regret. Because, before 9.6, each autovacuum freeze run scanned the entire table, and (on its first pass) potentially rewrote the entire table, it could be very high I/O, and when it woke up suddenly, it could cause performance issues. I thus recommended two things:
Increase autovacuum_freeze_max_age and vacuum_freeze_table_age, and,
Do manual VACUUM FREEZE operations on the “oldest” tables during low-traffic periods.
Unfortunately, far too many installations adopted recommendation #1, but didn’t do #2. The result was that they cranked up autovacuum_freeze_max_age so high that by the time the mandatory autovacuum freeze operation began, they were so close to transaction XID wraparound point, they had no choice but to take the system offline and do the operation in single-user mode.
Thus, I am forever rescinding that advice. Especially now that 9.6 is incremental, the I/O penalty of an autovacuum freeze is greatly reduced, and the consequences of not doing it are severe.
Don’t increase those parameters. Let autovacuum freeze do its job. If you want to stay ahead of it, we have a script to do opportunistic freezing that might be helpful.
Great news for all pgCenter users - a new version 0.6.0 has been released with new features and few minor improvements.
Here are some major changes:
new wait events profiler - a new sub-command which allows to inspect long-running queries and understand what query spends its time on.
goreleaser support - goreleaser helps to build binary packages for you, so you can find .rpm and .deb packages on the releases page.
Goreport card A+ status - A+ status is the little step to make code better and align it to Golang code style
This release also includes following minor improvements and fixes:
report tool now has full help list of supported stats, you can, at any time, get a descriptive explanation of stats provided by pgCenter. Check out the “--describe” flag of “pgcenter report”;
“pgcenter top” now has been fixed and includes configurable aligning of columns, which make stats viewing more enjoyable (check out builtin help for new hotkeys);
wrong handling of group mask has been fixed. It is used for canceling group of queries, or for termination of backends’ groups;
also fixed the issue when pgCenter is failed to connect to Postgres with disabled SSL;
and done some other minor internal refactoring.
New release is available here. Check it out and have a nice day.
We recently installed PostgreSQL 11 on an Ubuntu 18.04 using apt.postgresql.org. Many of our favorite extensions were already available via apt (postgis, ogr_fdw to name a few), but it didn't have the http extension we use a lot. The http extension is pretty handy for querying things like Salesforce and other web api based systems. We'll outline the basic compile and install steps. While it's specific to the http extension, the process is similar for any other extension you may need to compile.
I saw AT TIME ZONE used in a query, and found it confusing. I read the Postgres
documentation and was still confused, so I played with some queries and
finally figured it out. I then updated the Postgres documentation to explain it better, and here is what I found.
First, AT TIME ZONE has two capabilities. It allows time zones to be added to date/time values that lack them (timestamp without time zone,
::timestamp), and allows timestamp with time zone values (::timestamptz) to be shifted to non-local time zones and the time zone designation removed.
In summary, it allows:
timestamp without time zone&roarr timestamp with time zone (add time zone)
timestamp with time zone&roarr timestamp without time zone (shift time zone)
It is kind of odd for AT TIME ZONE to be used for both purposes, but the SQL standard requires this.
A feature of PostgreSQL that most people don’t even know exists is the ability to export and import transaction snapshots.
The documentation is accurate, but it doesn’t really describe why one might want to do such a thing.
First, what is a “snapshot”? You can think of a snapshot as the current set of committed tuples in the database, a consistent view of the database. When you start a transaction and set it to REPEATABLE READ mode, the snapshot remains consistent throughout the transaction, even if other sessions commit transactions. (In the default transaction mode, READ COMMITTED, each statement starts a new snapshot, so newly committed work could appear between statements within the transaction.)
However, each snapshot is local to a single transaction. But suppose you wanted to write a tool that connected to the database in multiple sessions, and did analysis or extraction? Since each session has its own transaction, and the transactions start asynchronously from each other, they could have different views of the database depending on what other transactions got committed. This might generate inconsistent or invalid results.
This isn’t theoretical: Suppose you are writing a tool like pg_dump, with a parallel dump facility. If different sessions got different views of the database, the resulting dump would be inconsistent, which would make it useless as a backup tool!
The good news is that we have the ability to “synchronize” various sessions so that they all use the same base snapshot.
First, a transaction opens and sets itself to REPEATABLE READ or SERIALIZABLE mode (there’s no point in doing exported snapshots in READ COMMITTED mode, since the snapshot will get replaced at the very next transaction). Then, that session calls pg_export_snapshot. This creates an identifier for the current transaction snapshot.
Then, the client running the first session passes that identifier to the clients that will be using it. You’ll need to do this via some non-database channel. For example, you can’t use LISTEN / NOTIFY, since the message isn’t actually sent until COMMIT time.
Each client that receives the snapshot ID can then do SET TRANSACTION SNAPSHOT ... to use the snapshot. The client needs to call this before it does any work in the session (even SELECT). Now, each of the clients has the same view into the database, and that view will remain until it COMMITs or ABORTs.
Note that each transaction is still fully autonomous; the various sessions are not “inside” the same transaction. They can’t see each other’s work, and if two different clients modify the database, those modifications are not visible to any other session, including the ones that are sharing the snapshot. You can think of the snapshot as the “base” view of the database, but each session can modify it (subject, of course, to the usual rules involved in modifying the same tuples, or getting serialization failures).
This is a pretty specialized use-case, of course; not many applications need to have multiple sessions with a consistent view of the database. But if you do, PostgreSQL has the facilities to do it!
Braintree Payments uses PostgreSQL as its primary datastore. We rely heavily on the data safety and consistency guarantees a traditional relational database offers us, but these guarantees come with certain operational difficulties. To make things even more interesting, we allow zero scheduled functional downtime for our main payments processing services.
Several years ago we published a blog post detailing some of the things we had learned about how to safely run DDL (data definition language) operations without interrupting our production API traffic.
Since that time PostgreSQL has gone through quite a few major upgrade cycles — several of which have added improved support for concurrent DDL. We’ve also further refined our processes. Given how much has changed, we figured it was time for a blog post redux.
For all code and database changes, we require that:
Live code and schemas be forward-compatible with updated code and schemas: this allows us to roll out deploys gradually across a fleet of application servers and database clusters.
New code and schemas be backward-compatible with live code and schemas: this allows us to roll back any change to the previous version in the event of unexpected errors.
For all DDL operations we require that:
Any exclusive locks acquired on tables or indexes be held for at most ~2 seconds.
Rollback strategies do not involve reverting the database schema to its previous version.
Transactionality
PostgreSQL supports transactional DDL. In most cases, you can execute multiple DDL statements inside an explicit database transaction and take an “all or nothing” approach to a set of changes. However, running multiple DDL statements inside a transaction has one serious downside: if you alter multiple objects, you’ll need to acquire exclusive locks on all of those objects in a single transactions. Because locks on multiple tables creates the possibility of deadlock and increases exposure to long waits, we do not combine multiple DDL statements into a single transaction. PostgreSQL will still execute each separate DDL statement transactionally; each statement will be either cleanly applied or fail and the transaction rolled back.
Note: Concurrent index creation is a special case. Postgres disallows executing CREATE INDEX CONCURRENTLY inside an explicit transaction; instead Postgres itself manages the transactions. If for some reason the index build fails before completion, you may need to drop the index before retrying, though the index will still never be used for regular queries if it did not finish building successfully.
Locking
PostgreSQL has many different levels of locking. We’re concerned primarily with the following table-level locks since DDL generally operates at these levels:
ACCESS EXCLUSIVE: blocks all usage of the locked table.
SHARE ROW EXCLUSIVE: blocks concurrent DDL against and row modification (allowing reads) in the locked table.
SHARE UPDATE EXCLUSIVE: blocks concurrent DDL against the locked table.
Note: “Concurrent DDL” for these purposes includes VACUUM and ANALYZE operations.
All DDL operations generally necessitate acquiring one of these locks on the object being manipulated. For example, when you run:
PostgreSQL attempts to acquire an ACCESS EXCLUSIVE lock on the table foos. Atempting to acquire this lock causes all subsequent queries on this table to queue until the lock is released. In practice your DDL operations can cause other queries to back up for as long as your longest running query takes to execute. Because arbitrarily long queueing of incoming queries is indistinguishable from an outage, we try to avoid any long-running queries in databases supporting our payments processing applications.
But sometimes a query takes longer than you expect. Or maybe you have a few special case queries that you already know will take a long time. PostgreSQL offers some additional runtime configuration options that allow us to guarantee query queueing backpressure doesn’t result in downtime.
Instead of relying on Postgres to lock an object when executing a DDL statement, we acquire the lock explicitly ourselves. This allows us to carefully control the time the queries may be queued. Additionally when we fail to acquire a lock within several seconds, we pause before trying again so that any queued queries can be executed without significantly increasing load. Finally, before we attempt lock acquisition, we query pg_locks¹ for any currently long running queries to avoid unnecessarily queueing queries for several seconds when it is unlikely that lock acquisition is going to succeed.
Starting with Postgres 9.3, you adjust the lock_timeout parameter to control how long Postgres will allow for lock acquisition before returning without acquiring the lock. If you happen to be using 9.2 or earlier (and those are unsupported; you should upgrade!), then you can simulate this behavior by using the statement_timeout parameter around an explicit LOCK <table> statement.
In many cases an ACCESS EXCLUSIVE lock need only be held for a very short period of time, i.e., the amount of time it takes Postgres to update its "catalog" (think metadata) tables. Below we'll discuss the cases where a lower lock level is sufficient or alternative approaches for avoiding long-held locks that block SELECT/INSERT/UPDATE/DELETE.
Note: Sometimes holding even an ACCESS EXCLUSIVE lock for something more than a catalog update (e.g., a full table scan or even rewrite) can be functionally acceptable when the table size is relatively small. We recommend testing your specific use case against realistic data sizes and hardware to see if a particular operation will be "fast enough". On good hardware with a table easily loaded into memory, a full table scan or rewrite for thousands (possibly even 100s of thousands) of rows may be "fast enough".
Table operations
Create table
In general, adding a table is one of the few operations we don’t have to think too hard about since, by definition, the object we’re “modifying” can’t possibly be in use yet. :D
While most of the attributes involved in creating a table do not involve other database objects, including a foreign key in your initial table definition will cause Postgres to acquire a SHARE ROW EXCLUSIVE lock against the referenced table blocking any concurrent DDL or row modifications. While this lock should be short-lived, it nonetheless requires the same caution as any other operation acquiring such a lock. We prefer to split these into two separate operations: create the table and then add the foreign key.
Drop table
Dropping a table requires an exclusive lock on that table. As long as the table isn’t in current use you can safely drop the table. Before allowing a DROP TABLE ... to make its way into our production environments we require documentation showing when all references to the table were removed from the codebase. To double check that this is the case you can query PostgreSQL's table statistics view pg_stat_user_tables² confirming that the returned statistics don't change over the course of a reasonable length of time.
Rename table
While it’s unsurprising that a table rename requires acquiring an ACCESS EXCLUSIVE lock on the table, that's far from our biggest concern. Unless the table is not being read from or written to, it's very unlikely that your application code could safely handle a table being renamed underneath it.
We avoid table renames almost entirely. But if a rename is an absolute must, then a safe approach might look something like the following:
Create a new table with the same schema as the old one.
Backfill the new table with a copy of the data in the old table.
Use INSERT and UPDATE triggers on the old table to maintain parity in the new table.
Begin using the new table.
Other approaches involving views and/or RULEs may also be viable depending on the performance characteristics required.
Column operations
Note: For column constraints (e.g., NOT NULL) or other constraints (e.g., EXCLUDES), see Constraints.
Add column
Adding a column to an existing table generally requires holding a short ACCESS EXCLUSIVE lock on the table while catalog tables are updated. But there are several potential gotchas:
Default values: Introducing a default value at the same time of adding the column will cause the table to be locked while the default value in propagated for all rows in the table. Instead, you should:
Add the new column (without the default value).
Set the default value on the column.
Backfill all existing rows separately.
Note: In the recently release PostgreSQL 11, this is no longer the case for non-volatile default values. Instead adding a new column with a default value only requires updating catalog tables, and any reads of rows without a value for the new column will magically have it “filled in” on the fly.
Not-null constraints: Adding a column with a NOT NULL constraint is only possible if there are no existing rows or a DEFAULT is also provided. If there are no existing rows, then the change is effectively equivalent to a catalog only change. If there are existing rows and you are also specifying a default value, then the same caveats apply as above with respect to default values.
Note: Adding a column will cause all SELECT * FROM ... style queries referencing the table to begin returning the new column. It is important to ensure that all currently running code safely handles new columns. To avoid this gotcha in our applications we require queries to avoid * expansion in favor of explicit column references.
Change column type
In the general case changing a column’s type requires holding an exclusive lock on a table while the entire table is rewritten with the new type.
There are a few exceptions:
Note: Even though one of the exceptions above was added in 9.1, changing the type of an indexed column would always rewrite the index even if a table rewrite was avoided. In 9.2 any column data type that avoids a table rewrite also avoids rewriting the associated indexes. If you’d like to confirm that your change won’t rewrite the table or any indexes, you can query pg_class³ and verify the relfilenode column doesn't change.
If you need to change the type of a column and one of the above exceptions doesn’t apply, then the safe alternative is:
Add a new column new_<column>.
Dual write to both columns (e.g., with a BEFORE INSERT/UPDATE trigger).
Backfill the new column with a copy of the old column’s values.
Rename <column> to old_<column> and new_<column> inside a single transaction and explicit LOCK <table> statement.
Drop the old column.
Drop column
It goes without saying that dropping a column is something that should be done with great care. Dropping a column requires an exclusive lock on the table to update the catalog but does not rewrite the table. As long as the column isn’t in current use you can safely drop the column. It’s also important to confirm that the column is not referenced by any dependent objects that could be unsafe to drop. In particular, any indexes using the column should be dropped separately and safely with DROP INDEX CONCURRENTLY since otherwise they will be automatically dropped along with the column under an ACCESS EXCLUSIVE lock. You can query pg_depend⁴ for any dependent objects.
Before allowing a ALTER TABLE ... DROP COLUMN ... to make its way into our production environments we require documentation showing when all references to the column were removed from the codebase. This process allows us to safely roll back to the release prior to the one that dropped the column.
Note: Dropping a column will require that you update all views, triggers, function, etc. that rely on that column.
Index operations
Create index
The standard form of CREATE INDEX ... acquires an ACCESS EXCLUSIVE lock against the table being indexed while building the index using a single table scan. In contrast, the form CREATE INDEX CONCURRENTLY ... acquires an SHARE UPDATE EXCLUSIVE lock but must complete two table scans (and hence is somewhat slower). This lower lock level allows reads and writes to continue against the table while the index is built.
Caveats:
Multiple concurrent index creations on a single table will not return from either CREATE INDEX CONCURRENTLY ... statement until the slowest one completes.
CREATE INDEX CONCURRENTLY ... may not be executed inside of a transaction but does maintain transactions internally. This holding open a transaction means that no auto-vacuums (against any table in the system) will be able to cleanup dead tuples introduced after the index build begins until it finishes. If you have a table with a large volume of updates (particularly bad if to a very small table) this could result in extremely sub-optimal query execution.
CREATE INDEX CONCURRENTLY ... must wait for all transactions using the table to complete before returning.
Drop index
The standard form of DROP INDEX ... acquires an ACCESS EXCLUSIVE lock against the table with the index while removing the index. For small indexes this may be a short operation. For large indexes, however, file system unlinking and disk flushing can take a significant amount of time. In contrast, the form DROP INDEX CONCURRENTLY ... acquires a SHARE UPDATE EXCLUSIVE lock to perform these operations allowing reads and writes to continue against the table while the index is dropped.
Caveats:
DROP INDEX CONCURRENTLY ... cannot be used to drop any index that supports a constraint (e.g., PRIMARY KEY or UNIQUE).
DROP INDEX CONCURRENTLY ... may not be executed inside of a transaction but does maintain transactions internally. This holding open a transaction means that no auto-vacuums (against any table in the system) will be able to cleanup dead tuples introduced after the index build begins until it finishes. If you have a table with a large volume of updates (particularly bad if to a very small table) this could result in extremely sub-optimal query execution.
DROP INDEX CONCURRENTLY ... must wait for all transactions using the table to complete before returning.
Note: DROP INDEX CONCURRENTLY ... was added in Postgres 9.2. If you're still running 9.1 or prior, you can achieve somewhat similar results by marking the index as invalid and not ready for writes, flushing buffers with the pgfincore extension, and the dropping the index.
Rename index
ALTER INDEX ... RENAME TO ... requires an ACCESS EXCLUSIVE lock on the index blocking reads from and writes to the underlying table. However a recent commit expected to be a part of Postgres 12 lowers that requirement to SHARE UPDATE EXCLUSIVE.
Reindex
REINDEX INDEX ... requires an ACCESS EXCLUSIVE lock on the index blocking reads from and writes to the underlying table. Instead we use the following procedure:
Create a new index concurrently that duplicates the existing index definition.
Rename the new index to match the original index’s name.
Note: If the index you need to rebuild backs a constraint, remember to re-add the constraint as well (subject to all of the caveats we’ve documented.)
Constraints
NOT NULL Constraints
Removing an existing not-null constraint from a column requires an exclusive lock on the table while a simple catalog update is performed.
In contrast, adding a not-null constraint to an existing column requires an exclusive lock on the table while a full table scan verifies that no null values exist. Instead you should:
Add a CHECK constraint requiring the column be not-null with ALTER TABLE <table> ADD CONSTRAINT <name> CHECK (<column> IS NOT NULL) NOT VALID;. The NOT VALID tells Postgres that it doesn't need to scan the entire table to verify that all rows satisfy the condition.
Manually verify that all rows have non-null values in your column.
Validate the constraint with ALTER TABLE <table> VALIDATE CONSTRAINT <name>;. With this statement PostgreSQL will block acquisition of other EXCLUSIVE locks for the table, but will not block reads or writes.
Bonus: There is currently a patch in the works (and possibly it will make it into Postgres 12) that will allow you to create a NOT NULL constraint without a full table scan if a CHECK constraint (like we created above) already exists.
Foreign keys
ALTER TABLE ... ADD FOREIGN KEY requires a SHARE ROW EXCLUSIVE lock (as of 9.5) on both the altered and referenced tables. While this won't block SELECT queries, blocking row modification operations for a long period of time is equally unacceptable for our transaction processing applications.
To avoid that long-held lock you can use the following process:
ALTER TABLE ... ADD FOREIGN KEY ... NOT VALID: Adds the foreign key and begins enforcing the constraint for all new INSERT/UPDATE statements but does not validate that all existing rows conform to the new constraint. This operation still requires SHARE ROW EXCLUSIVE locks, but the locks are only briefly held.
ALTER TABLE ... VALIDATE CONSTRAINT <constraint>: This operation checks all existing rows to verify they conform to the specified constraint. Validation requires a SHARE UPDATE EXCLUSIVE so may run concurrently with row reading and modification queries.
Check constraints
ALTER TABLE ... ADD CONSTRAINT ... CHECK (...) requires an ACCESS EXCLUSIVE lock. However, as with foreign keys, Postgres supports breaking the operation into two steps:
ALTER TABLE ... ADD CONSTRAINT ... CHECK (...) NOT VALID: Adds the check constraint and begins enforcing it for all new INSERT/UPDATE statements but does not validate that all existing rows conform to the new constraint. This operation still requires an ACCESS EXCLUSIVE lock.
ALTER TABLE ... VALIDATE CONSTRAINT <constraint>: This operation checks all existing rows to verify they conform to the specified constraint. Validation requires a SHARE UPDATE EXCLUSIVE on the altered table so may run concurrently with row reading and modification queries. A ROW SHARE lock is held on the reference table which will block any operations requiring exclusive locks while validating the constraint.
Uniqueness constraints
ALTER TABLE ... ADD CONSTRAINT ... UNIQUE (...) requires an ACCESS EXCLUSIVE lock. However, Postgres supports breaking the operation into two steps:
Create a unique index concurrently. This step will immediately enforce uniqueness, but if you need a declared constraint (or a primary key), then continue to add the constraint separately.
Add the constraint using the already existing index with ALTER TABLE ... ADD CONSTRAINT ... UNIQUE USING INDEX <index>. Adding the constraint still requires an ACCESS EXCLUSIVE lock, but the lock will only be held for fast catalog operations.
Note: If you specify PRIMARY KEY instead of UNIQUE then any non-null columns in the index will be made NOT NULL. This requires a full table scan which currently can't be avoided. See NOT NULL Constraints for more details.
Exclusion constraints
ALTER TABLE ... ADD CONSTRAINT ... EXCLUDE USING ... requires an ACCESS EXCLUSIVE lock. Adding an exclusion constraint builds the supporting index, and, unfortunately, there is currently no support for using an existing index (as you can do with a unique constraint).
Enum Types
CREATE TYPE <name> AS (...) and DROP TYPE <name> (after verifying there are no existing usages in the database) can both be done safely without unexpected locking.
Modifying enum values
ALTER TYPE <enum> RENAME VALUE <old> TO <new> was added in Postgres 10. This statement does not require locking tables which use the enum type.
Deleting enum values
Enums are stored internally as integers and there is no support for gaps in the valid range, removing a value would currently shifting values and rewriting all rows using those values. PostgreSQL does not currently support removing values from an existing enum type.
Announcing Pg_ha_migrations for Ruby on Rails
We’re also excited to announce that we have open-sourced our internal library pg_ha_migrations. This Ruby gem enforces DDL safety in projects using Ruby on Rails and/or ActiveRecord with an emphasis on explicitly choosing trade-offs and avoiding unnecessary magic (and the corresponding surprises). You can read more in the project’s README.
Footnotes
[1] You can find active long-running queries and the tables they lock with the following query:
I’ve learned a lot of skills over the course of my career, but no technical skill more useful than SQL. SQL stands out to me as the most valuable skill for a few reasons:
It is valuable across different roles and disciplines
Learning it once doesn’t really require re-learning
You seem like a superhero. You seem extra powerful when you know it because of the amount of people that aren’t fluent
Let me drill into each of these a bit further.
SQL a tool you can use everywhere
Regardless of what role you are in SQL will find a way to make your life easier. Today as a product manager it’s key for me to look at data, analyze how effective we’re being on the product front, and shape the product roadmap. If we just shipped a new feature, the data on whether someone has viewed that feature is likely somewhere sitting in a relational database. If I’m working on tracking key business metrics such as month over month growth, that is likely somewhere sitting in a relational database. At the other end of almost anything we do there is likely a system of record that speaks SQL. Knowing how to access it most natively saves me a significant amount of effort without having to go ask someone else the numbers.
But even before becoming a product manager I would use SQL to inform me about what was happening within systems. As an engineer it could often allow me to pull information I wanted faster than if I were to script it in say Ruby or Python. When things got slow in my webapp having an understanding of the SQL that was executed and ways to optimize it was indespensible. Yes, this was going a little beyond just a basic understanding of SQL… but adding an index to a query instead of rolling my own homegrown caching well that was well worth the extra time learning.
SQL is permanent
I recall roughly 20 years ago creating my first webpage. It was magical, and then I introduced some Javascript to make it even more impressive prompting users to click Yes/No or give me some input. Then about 10 years later jQuery came along and while it was a little more verbose at times and something new to learn it made things prettier overall so I committed to re-learning the jQuery approach to JS. Then it just picked up pace with Angular –> React/Ember, and now I have an entire pipeline to introduce basic Javascript into my website and the reality is I’m still trying to accomplish the same thing I was 20 years ago by having someone click Yes/No.
SQL in contrast doesn’t really change. Caveat: It has changed–there is modern sql, but I’d still argue less dramatically than other language landscapes. Yes we get a new standard every few years and occasionally something new comes along like support for window functions or CTEs, but the basics of SQL are pretty permanent. Learning SQL once will allow you to re-use it heavily across your career span without having to re-learn. Don’t get me wrong I love learning new things, but I’d rather learn something truly new than just yet another way to accomplish the same task.
SQL: Seem better than you are
SQL is an underlearned skill, the majority of application developers just skip over it. Because so few actually know SQL well you can seem more elite than you actually are. In past companies with hundreds of engineers I’d get a question several times a week from junior to principal engineers of: “hey can you help me figure out how to write a query for this?” Because you’re skilled at something so few others are you can help them out which always makes life a little easier when you have a question for them.
So if you’re not already proficient what are you waiting for, do you want to seem like a SQL badass yet?
When data are naturally aligned, CPU can perform read and write to memory efficiently. Hence, each data type in PostgreSQL has a specific alignment requirement. When multiple attributes are stored consecutively in a tuple, padding is inserted before an attribute so that it begins from the required aligned boundary. A better understanding of these alignment requirements may help minimizing the amount of padding required while storing a tuple on disk, thus saving disk space.
Data types in Postgres are divided into following categories:
Pass-by-value, fixed length: Data types that are passed by values to Postgres internal routines and have fixed lengths fall into this category.. The length can be 1, 2, or 4 (or 8 on 64-bit systems) bytes.
Pass-by-reference, fixed length: For these data types, an address reference from the in-memory heap page is sent to internal Postgres routines. They also have fixed lengths.
Pass-by_reference, variable length: For variable length data types, Postgres prepends a varlena header before the actual data. It stores some information about how the data is actually stored on-disk (uncompressed, compressed or TOASTed) and the actual length of the data. For TOASTed attributes, the actual data is stored in a separate relation. In these cases, the varlena headers follow some information about the actual location of the data in their corresponding TOAST relation.
Typically, on-disk size of a varlena header is 1-byte. But, if the data cannot be toasted and size of the uncompressed data crosses 126 bytes, it uses a 4-bytes header. For example,
CREATE TABLE t1 ( , a varchar ); insert into t1 values(repeat('a',126)); insert into t1 values(repeat('a',127)); select pg_column_size(a) from t1; pg_column_size --------------------- 127 131
Besides, attributes having 4-bytes varlena header need to be aligned to a 4-bytes aligned memory location. It may waste upto 3-bytes of additional padding space. So, some careful length restrictions on such columns may save space.
Pass-by_reference, variable length(cstring, unknown): Finally, there are two data types, viz. ctring and unknown, which are string literals. They can be stored from any 1-byte aligned boundary. Also, they do not require any varlena header.
You can check the alignment requirements of each type using the following query,
select typname,typbyval,typlen,typalign from pg_type;
where typname is name of the data type; typbyval is true if the data type is accessed as passed-by-value, else false; typlen is the actual length of the data type, however for data-types of variable length it has a value < 0 (-2 for cstring and unknown, -1 otherwise); typalign is the required alignment for the data type.
After checking the alignment requirement of each data type, you can reduce the padding space by positioning them in their alignment-favourable way. For example, following table schema wastes a lot of disk space for padding:
CREATE TABLE t1 ( , a char , b int2 -- 1 byte of padding after a , c char , d int4 -- 3 bytes of padding after c , e char , f int8 -- 7 bytes of padding after e );
If you reorder the columns as double aligned column first, int aligned, short aligned and char aligned column in last, you can save (1+3+7)=11 bytes of space per tuple.
CREATE TABLE t1 ( , f int8 , d int4 , b int2 , a char , c char , e char );
Before the tuple attributes, a fixed size 23-byte tuple header followed by an optional null-bitmap and an optional object ID are stored. The attributes always starts from a MAXALIGN-ed boundary - typically 8 bytes on a 64-bit OS (or 4 bytes on a 32-bit OS). So, the effective size of a minimal tuple header is 24-bytes (23-bytes header + 1-byte padding). When the null-bitmap is present, it occupies enough bytes to have one bit per data column. In this list of bits, a 1 bit indicates not-null, a 0 bit is a null. When the bitmap is not present, all columns are assumed not-null. For example[3],
This includes the 23-bytes fixed-sized tuple header and a null-bitmap consisting of 8-bits. Now, if we increase the number of columns to nine, it includes 23-bytes fixed-sized tuple header, a null-bitmap consisting of 16-bits and 7 bytes of padding.
Saving a few bytes per tuple in a relation consisting of millions of rows may result in saving some significant storage space. Besides, if we can fit more tuple in a data page, performance can be improved due to lesser I/O activity.
You might not be aware that you can store a virtual row, called a composite value, inside a database field. Composite values have their own column names and data types.
This is useful if you want to group multiple statically-defined columns inside a single column. (The
JSON data types are ideal for dynamically-defined columns.)
This email thread explains how to define and
use them, I have a presentation that mentions them, and the Postgres
manual has a section about them.
I want to take a few minutes for a deep dive into the effect your data model has on storage density when using PostgreSQL. When this topic came up with a customer, I explained my thoughts on the matter, but I realized at the time that I had never done a reasonably careful apples-to-apples test to see just exactly what the effect is, at least for a model sample size of one. So here it is.
PostgreSQL is emerging as the standard destination for database migrations from proprietary databases. As a consequence, there is an increase in demand for database side code migration and associated performance troubleshooting. One might be able to trace the latency to a plsql function, but explaining what happens within a function could be a difficult question. Things get messier when you know the function call is taking time, but within that function there are calls to other functions as part of its body. It is a very challenging question to identify which line inside a function—or block of code—is causing the slowness. In order to answer such questions, we need to know how much time an execution spends on each line or block of code. The plprofiler project provides great tooling and extensions to address such questions.
Demonstration of plprofiler using an example
The plprofiler source contains a sample for testing plprofiler. This sample serves two purposes. It can be used for testing the configuration of plprofiler, and it is great place to see how to do the profiling of a nested function call. Files related to this can be located inside the “examples” directory. Don’t worry—I’ll be running through the installation of plprofiler later in this article.
$ cd examples/
The example expects you to create a database with name “pgbench_plprofiler”
The project provides a shell script along with a source tree to test plprofiler functionality. So testing is just a matter of running the shell script.
$ ./prepdb.sh
dropping old tables...
....
Running session level profiling
This profiling uses session level local-data. By default the plprofiler extension collects runtime data in per-backend hashtables (in-memory). This data is only accessible in the current session, and is lost when the session ends or the hash tables are explicitly reset. plprofiler’s run command will execute the plsql code and capture the profile information.
What happens during above plprofiler command run can be summarised in 3 steps:
A function call with four parameters “SELECT tpcb(1, 2, 3, -42)” is presented to the plprofiler tool for execution.
plprofiler establishes a connection to PostgreSQL and executes the function
The tool collects the profile information captured in the local-data hash tables and generates an HTML report “tpcb-test1.html”
Global profiling
As mentioned previously, this method is useful if we want to profile the function executions in other sessions or on the entire database. During global profiling, data is captured into a shared-data hash table which is accessible for all sessions in the database. The plprofiler extension periodically copies the local-data from the individual sessions into shared hash tables, to make the statistics available to other sessions. See the
plprofiler monitor
command, below, for details. This data still relies on the local database system catalog to resolve Oid values into object definitions.
In this example, the plprofiler tool will be running in monitor mode for a duration of 60 seconds. Every 10 seconds, the tool copies data from local-data to shared-data.
The data in shared-data will be retained until it’s explicitly cleared using the
plprofiler reset
command
$ plprofiler reset
If there is no profile data present in the shared hash tables, execution of the report will result in error message.
$ plprofiler report --from-shared --title=MultipgMax --output=MultipgMax.html
Traceback (most recent call last):
File "/usr/bin/plprofiler", line 11, in <module>
load_entry_point('plprofiler==4.dev0', 'console_scripts', 'plprofiler')()
File "/usr/lib/python2.7/site-packages/plprofiler-4.dev0-py2.7.egg/plprofiler/plprofiler_tool.py", line 67, in main
return report_command(sys.argv[2:])
File "/usr/lib/python2.7/site-packages/plprofiler-4.dev0-py2.7.egg/plprofiler/plprofiler_tool.py", line 493, in report_command
report_data = plp.get_shared_report_data(opt_name, opt_top, args)
File "/usr/lib/python2.7/site-packages/plprofiler-4.dev0-py2.7.egg/plprofiler/plprofiler.py", line 555, in get_shared_report_data
raise Exception("No profiling data found")
Exception: No profiling data found
Report on profile information
The HTML report generated by plprofiler is a self-contained HTML document and it gives detailed information about the PL/pgSQL function execution. There will be a clickable FlameGraph at the top of the report with details about functions in the profile. The plprofiler FlameGraph is based on the actual Wall-Clock time spent in the PL/pgSQL functions. By default, plprofiler provides details on the top ten functions, based on their self_time (total_time – children_time).
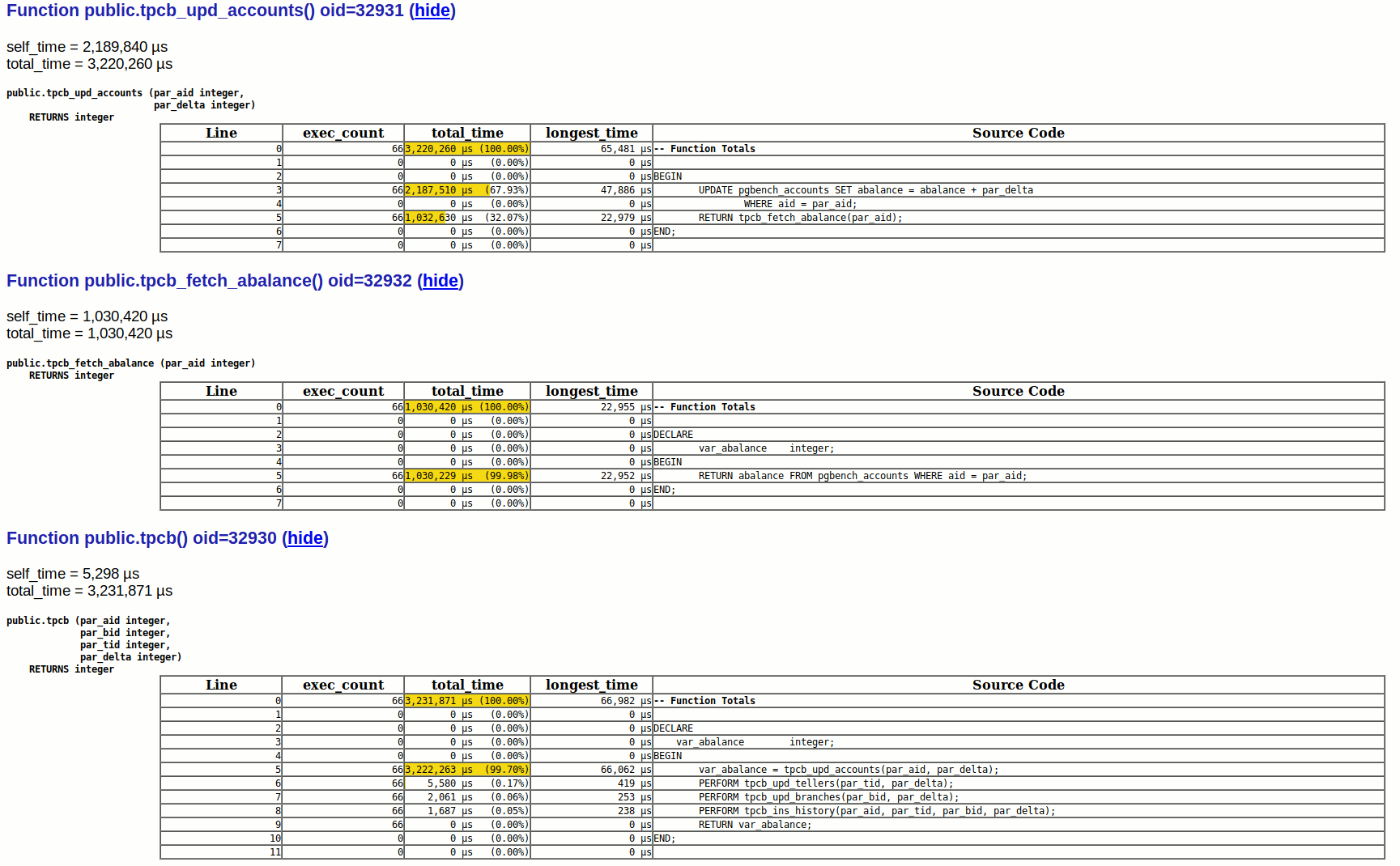
This section of the report is followed by tabular representation of function calls. For example:
This gives a lot of detailed information such as execution counts and time spend against each line of code.
Binary Packages
Binary distributions of plprofiler are not common. However the BigSQL project provides plprofiler packages as an easy to use bundle. Such ready-to-use packages are one of the reasons for BigSQL to remain as one of the most developer friendly PostgreSQL distributions. The first screen of Package manager installation of BigSQL provided me with the information I am looking for:
Appears that there was a recent release of BigSQL packages and plprofiler is an updated package within that.
As we can see, even PostgreSQL parameters are updated to have plprofiler as a
shared_preload_library
. If need to use plprofiler for investigating code, these binary packages from the BigSQL project are my first preference because everything is ready to use. Definitely, this is developer-friendly.
Creation of extension and configuring the plprofiler tool
At the database level, we should create the plprofiler extension to profile the function execution. This step needs to be performed in both cases, whether we want global profiling where share_preload_libraries are set, or at session level where that is not required
plprofiler is not just an extension, but comes with tooling to invoke profiling or to generate reports. These scripts are primarily coded in Python and uses psycopg2 to connect to PostgreSQL. The python code is located inside the “python-plprofiler” directory of the source tree. There are a few perl dependencies too which will be resolved as part of installation
If you already have a PostgreSQL instance running using binaries from PGDG repository OR you want to wet your hands by building everything from source, then installation needs a different approach. I have PostgreSQL 11 already running on the system. The first step is to get the corresponding development packages which have all the header files and libraries to support a build from source. Obviously this is the thorough way of getting plprofiler working.
$ sudo yum install postgresql11-devel
We need to have build tools, and since the core of plprofiler is C code, we have to install a C compiler and make utility.
$ sudo yum install gcc make
Preferably, we should build plprofiler using the same OS user that runs PostgreSQL server, which is “postgres” in most environments. Please make sure that all PostgreSQL binaries are available in the path and that you are able to execute the pg_config, which lists out build related information:
The above command expects all build tools to be in the proper path even with sudo.
Profiling external sessions
To profile a function executed by another session, or all other sessions, we should load the libraries at global level. In production environments, that will be the case. This can be done by adding the extension library to the
shared_preload_libraries
specification. You won’t need this if you only want to profile functions executed within your session. Session level profiling is generally possible only in Dev/Test environments.
To enable global profiling, verify the current value of
shared_preload_libraries
and add plprofiler to the list.
postgres=# show shared_preload_libraries ;
shared_preload_libraries
--------------------------
(1 row)
postgres=# alter system set shared_preload_libraries = 'plprofiler';
ALTER SYSTEM
postgres=#
This change requires us to restart the PostgreSQL server
$ sudo systemctl restart postgresql-11
After the restart, it’s a good idea to verify the parameter change
postgres=# show shared_preload_libraries ;
shared_preload_libraries
--------------------------
plprofiler
(1 row)
From this point onwards, the steps are same as those for the binary package setup discussed above.
Summary
plprofiler is a wonderful tool for developers. I keep seeing many users who are in real need of it. Hopefully this blog post will help those who never tried it.
The right application of indexes can make queries blazing fast.
Indexes use pointers to access data pages in a speedy fashion.
Major changes happened on Indexes in PostgreSQL 11, lots of much awaited patches have been released.
Let's have a look at some of the great features of this release.
Parallel B-TREE Index Builds
PostgreSQL 11 introduced an infrastructure patch to enable parallel index creation.
It can be only used with B-Tree index as for now.
Building a parallel B-Tree index is two to three times faster than doing the same thing without parallel working (or serial build).
In PostgreSQL 11 parallel index creation is on by default.
There are two important parameters:
max_parallel_workers - Sets the maximum number of workers that the system can support for parallel queries.
max_parallel_maintenance_workers - Controls the maximum number of worker processes which can be used to CREATE INDEX.
Let's check it with an example:
severalnines=# CREATE TABLE test_btree AS SELECT generate_series(1,100000000) AS id;
SELECT 100000000
severalnines=# SET maintenance_work_mem = '1GB';
severalnines=# \timing
severalnines=# CREATE INDEX q ON test_btree (id);
TIME: 25294.185 ms (00:25.294)
Let's try it with 8-way parallel work:
severalnines=# SET maintenance_work_mem = '2GB';
severalnines=# SET max_parallel_workers = 16;
severalnines=# SET max_parallel_maintenance_workers = 8;
severalnines=# \timing
severalnines=# CREATE INDEX q1 ON test_btree (id);
TIME: 11001.240 ms (00:11.001)
We can see the performance difference with the parallel worker, more than 60% performant with just a small change. The maintenance_work_mem can also be increased to get more performance.
The ALTER table also helps to increase parallel workers. Below syntax can be used to increase parallel workers along with max_parallel_maintenance_workers. This bypasses the cost model completely.
ALTER TABLE test_btree SET (parallel_workers = 24);
Tip: RESET to default once the index build is completed to prevent adverse query plan.
CREATE INDEX with the CONCURRENTLY option supports parallel builds without special restrictions, only the first table scan is actually performed in parallel.
Add predicate locking for Hash, Gist, and Gin Indexes
PostgreSQL 11 shipped with predicate lock support for hash indexes, gin indexes, and gist indexes. These will make SERIALIZABLE transaction isolation much more efficient with those indexes.
Benefit: predicate locking can provide better performance at serializable isolation level by reducing the number of false positives which leads to unnecessary serialization failure.
In PostgreSQL 10, the lock range is the relation, but in PostgreSQL 11 lock is found to be page only.
Let’s test it out.
severalnines=# CREATE TABLE sv_predicate_lock1(c1 INT, c2 VARCHAR(10)) ;
CREATE TABLE
severalnines=# CREATE INDEX idx1_sv_predicate_lock1 ON sv_predicate_lock1 USING 'hash(c1) ;
CREATE INDEX
severalnines=# INSERT INTO sv_predicate_lock1 VALUES (generate_series(1, 100000), 'puja') ;
INSERT 0 100000
severalnines=# BEGIN ISOLATION LEVEL SERIALIZABLE ;
BEGIN
severalnines=# SELECT * FROM sv_predicate_lock1 WHERE c1=10000 FOR UPDATE ;
c1 | c2
-------+-------
10000 | puja
(1 row)
As we can see below, the lock is on page level instead of relation. In PostgreSQL 10 it was on relation level, so it’s a BIG WIN for concurrent transactions in PostgreSQL 11.
Tip: A sequential scan will always need a relation-level predicate lock. This can result in an increased rate of serialization failures. It may be helpful to encourage the use of index scans by reducing random_page_cost and/or increasing cpu_tuple_cost.
The Heap Only Tuple (HOT) feature, eliminates redundant index entries and allows the re-use of space taken by DELETEd or obsoleted UPDATEd tuples without performing a table-wide vacuum. It reduces index size by avoiding the creation of identically-keyed index entries.
If the value of an index expression is unchanged after UPDATE, allow HOT updates where previously PostgreSQL disallowed them, giving a significant performance boost in those cases.
This is especially useful for indexes such as JSON->>field where the JSON value changes but the indexed value does not.
This feature was rolled back in 11.1 due to performance degradation (AT Free BSD only as per Simon), more details / benchmark can be found here. This should be fixed in future release.
Allow entire Hash index pages to be scanned
Hash index: The query planner will consider using a hash index whenever an indexed column is involved in a comparison using the = operator. It was also not crash safe (not logged in WAL) so it needs to rebuild after DB crashes, and changes to hash were not written via streaming replication.
In PostgreSQL 10, the hash index was WAL logged, that means, it’s CRASH safe and can be replicated. Hash indexes use much less space compare to B-Tree so they can fit better in memory.
In PostgreSQL 11, Btree indexes have an optimization called "single page vacuum", which opportunistically removes dead index pointers from index pages, preventing a huge amount of index bloat, which would otherwise occur. The same logic has been ported to Hash indexes. It accelerates space recycling, reducing bloat.
STATISTICS of function index
It is now possible to specify a STATISTICS value for a function index column. It's highly valuable to the efficiency of a specialized application. We can now collect stats on expression columns, that will help the planner to take a more accurate decision.
severalnines=# CREATE INDEX idx1_stats ON stat ((s1 + s2)) ;
CREATE INDEX
severalnines=# ALTER INDEX idx1_stats ALTER COLUMN 1 SET STATISTICS 1000 ;
ALTER INDEX
severalnines=# \d+ idx1_stats
Index "public.idx1_stats"
Column | Type | Definition | Storage | Stats target
--------+---------+------------+---------+--------------
expr | numeric | (c1 + c2) | main | 1000
btree, for table "public.stat1"
amcheck
A new Contrib module amcheck has been added. Only B-Tree indexes can be checked.
Let's test it out !
severalnines=# CREATE EXTENSION amcheck ;
CREATE EXTENSION
severalnines=# SELECT bt_index_check('idx1_stats') ;
ERROR: invalid page in block 0 of relation base/16385/16580
severalnines=#CREATE INDEX idx1_hash_data1 ON data1 USING hash (c1) ;
CREATE INDEX
severalnines=# SELECT bt_index_check('idx1_hash_data1') ;
ERROR: only B-Tree indexes are supported as targets for verification
DETAIL: Relation "idx1_hash_data1" is not a B-Tree index.
Local partitioned Index possible
Prior to PostgreSQL11, It was not possible to create an index on a child table or a partitioned table.
In PostgreSQL 11, when CREATE INDEX is run on a partitioned table / parent table, it creates catalog entries for an index on the partitioned table and cascades to create actual indexes on the existing partitions. It will create them in future partitions also.
Let's try to create a parent table and a partition it:
severalnines=# create table test_part ( a int, list varchar(5) ) partition by list (list);
CREATE TABLE
severalnines=# create table part_1 partition of test_part for values in ('India');
CREATE TABLE
severalnines=# create table part_2 partition of test_part for values in ('USA');
CREATE TABLE
severalnines=#
severalnines=# \d+ test_part
Table "public.test_part"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+----------------------+-----------+----------+---------+----------+--------------+-------------
a | integer | | | | plain | |
list | character varying(5) | | | | extended | |
Partition key: LIST (list)
Partitions: part_1 FOR VALUES IN ('India'),
part_2 FOR VALUES IN ('USA')
Let's try to create an index on the parent table:
severalnines=# create index i_test on test_part (a);
CREATE INDEX
severalnines=# \d part_2
Table "public.part_2"
Column | Type | Collation | Nullable | Default
--------+----------------------+-----------+----------+---------
a | integer | | |
list | character varying(5) | | |
Partition of: test_part FOR VALUES IN ('USA')
Indexes:
"part_2_a_idx" btree (a)
severalnines=# \d part_1
Table "public.part_1"
Column | Type | Collation | Nullable | Default
--------+----------------------+-----------+----------+---------
a | integer | | |
list | character varying(5) | | |
Partition of: test_part FOR VALUES IN ('India')
Indexes:
"part_1_a_idx" btree (a)
The index is cascaded down to all the partitions in PostgreSQL 11, which is a really cool feature.
Covering Index (include CLAUSE for indexes)
An INCLUDE clause to add columns to the index can be specified. This is effective when adding columns which are unrelated to a unique constraint of a unique index. The INCLUDE columns exists solely to allow more queries to benefit from index-only scans. Only B-tree indexes support INCLUDE clause as for now.
Let's check the behavior without INCLUDE. It won't use index only scan if additional columns appear in the SELECT. This can be achieved by using INCLUDE clause.
severalnines=# CREATE TABLE no_include (a int, b int, c int);
CREATE TABLE
severalnines=# INSERT INTO no_include SELECT 3 * val, 3 * val + 1, 3 * val + 2 FROM generate_series(0, 1000000) as val;
INSERT 0 1000001
severalnines=# CREATE UNIQUE INDEX old_unique_idx ON no_include(a, b);
CREATE INDEX
severalnines=# VACUUM ANALYZE;
VACUUM
EXPLAIN ANALYZE SELECT a, b FROM no_include WHERE a < 1000; - It will do index only scan
EXPLAIN ANALYZE SELECT a, b, c FROM no_include WHERE a < 1000; - It will not do index only scan as we have extra column in select.
severalnines=# CREATE INDEX old_idx ON no_include (a, b, c);
CREATE INDEX
severalnines=# VACUUM ANALYZE;
VACUUM
severalnines=# EXPLAIN ANALYZE SELECT a, b, c FROM no_include WHERE a < 1000; - It did index only scan as index on all three columns.
QUERY PLAN
-------------------------------------------------
Index Only Scan using old_idx on no_include
(cost=0.42..14.92 rows=371 width=12)
(actual time=0.086..0.291 rows=334 loops=1)
Index Cond: (a < 1000)
Heap Fetches: 0
Planning Time: 2.108 ms
Execution Time: 0.396 ms
(5 rows)
Let's try with include clause. In the example below the UNIQUE CONSTRAINT is created in columns a and b, but the index includes a c column.
severalnines=# CREATE TABLE with_include (a int, b int, c int);
CREATE TABLE
severalnines=# INSERT INTO with_include SELECT 3 * val, 3 * val + 1, 3 * val + 2 FROM generate_series(0, 1000000) as val;
INSERT 0 1000001
severalnines=# CREATE UNIQUE INDEX new_unique_idx ON with_include(a, b) INCLUDE (c);
CREATE INDEX
severalnines=# VACUUM ANALYZE;
VACUUM
severalnines=# EXPLAIN ANALYZE SELECT a, b, c FROM with_include WHERE a < 10000;
QUERY PLAN
-----------------------------------------------------
Index Only Scan using new_unique_idx on with_include
(cost=0.42..116.06 rows=3408 width=12)
(actual time=0.085..2.348 rows=3334 loops=1)
Index Cond: (a < 10000)
Heap Fetches: 0
Planning Time: 1.851 ms
Execution Time: 2.840 ms
(5 rows)
There cannot be any overlap between columns in the main column list and those from the include list
severalnines=# CREATE UNIQUE INDEX new_unique_idx ON with_include(a, b) INCLUDE (a);
ERROR: 42P17: included columns must not intersect with key columns
LOCATION: DefineIndex, indexcmds.c:373
A column used with an expression in the main list works:
severalnines=# CREATE UNIQUE INDEX new_unique_idx_2 ON with_include(round(a), b) INCLUDE (a);
CREATE INDEX
Expressions cannot be used in an include list because they cannot be used in an index-only scan:
severalnines=# CREATE UNIQUE INDEX new_unique_idx_2 ON with_include(a, b) INCLUDE (round(c));
ERROR: 0A000: expressions are not supported in included columns
LOCATION: ComputeIndexAttrs, indexcmds.c:1446
Conclusion
The new features of PostgreSQL will surely improve the lives of DBAs so it's heading to become a strong alternative choice in open source DB. I understand that a few features of indexes are currently limited to B-Tree, it is still a great start of Parallel execution era for PostgreSQL and heading to a nice tool to look closely. Thanks!
This article explains this race and covers other improvements in PostgreSQL 11.
Complete SQL:2011 Over Clause
The over clause defines which rows are visible to a window function. Window functions were originally standardized with SQL:2003, and PostgreSQL has supported them since PostgreSQL 8.4 (2009). In some areas, the PostgreSQL implementation was less complete than the other implementations (range frames, ignore nulls), but in other areas it was the first major system to support them (the window clause). In general, PostgreSQL was pretty close to the commercial competitors, and it was the only major free database to support window functions at all—until recently.
In 2017, MariaDB introduced window functions. MySQL and SQLite followed in 2018. At that time, the MySQL implementation of the over clause was even more complete than that of PostgreSQL, a gap that PostgreSQL 11 closed. Furthermore, PostgreSQL is again the first to support some aspects of the over clause, namely the frame unit groups and frame exclusion. These are not yet supported by any other major SQL database—neither open-source, nor commercial.
The only over clause feature not supported by PostgreSQL 11 are pattern and related clauses. These clauses were just standardized with SQL:2016 and do a framing based on a regular expression. No major database supports this this framing yet.1
Frame Units
Before looking into the new functionality in PostgreSQL 11, I’ll show you a typical use case of window functions. We can then proceed to the so-called framing.
The example calculates the running total over the column amnt, so the sum over all rows before and up to the current row according to the specified order by clause:
SELECT SUM(amnt)
OVER(ORDER BY id
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) running_total
FROM …
The aggregate function sum is used with the over clause rather than with a group by clause—that makes it a window function. The interesting part in this example is the framing, which is in bold.
Window framing narrows an ordered window to the rows between a specified start and end row.
The general syntax is:
<unit> BETWEEN <window frame bound>
AND <window frame bound>
[<frame exclusion>]
Let’s start with the window frame bounds, i.e. the definition of the frame’s beginning and end.
The window frame bounds can be specified in terms relative to the current row or they can be “unbounded”. Unbounded refers to the start or end of the current result or partition.
CURRENT ROW
| <distance> (PRECEDING|FOLLOWING)
| UNBOUNDED (PRECEDING|FOLLOWING)
The following frame definition uses frame bounds relative to the current row.
<unit> BETWEEN 1 PRECEDING AND CURRENT ROW
To truly understand the meaning of relative bounds, we must also understand how the three frame units—rows, range, and groups—change the meaning of these bounds.
The rows unit does just what you might expect: it interprets current row as referring to the current row and <distance> in preceding and following as a number of rows. With the rows unit, the previous example defines a frame that includes up to two rows: one before the current row and the current row itself. If there is no row before the current row, e.g. because the current row is the first row, the frame just covers the current row itself.
The next frame unit, range, does not count rows at all. Instead it uses the value of the sort key (order by expression) and adds or subtracts the specified <distance>. All rows for which the value of the sort key falls into the specified range are taken into the frame.
Note that current row as range bound refers to all rows with the same value as the current row. That can be many rows. Think of current row as though it was 0 preceding or 0 following.2 In case of range, “current peers” or “current value” might have been a better choice than current row.
The following figure uses the unit range instead of rows. As the value of the current row is two, the frame covers all rows with the values one to two (inclusive). The frame begins at the first row, because its value is one and thus falls into the value range. The end of the frame is even beyond the current row as the next row still falls into the value range.
This is an example that works in MySQL 8.0, but not in PostgreSQL prior to version 11. Although range frames were supported by PostgreSQL before, you could not use a numeric distance as shown above. Only unbounded and current row could be used before PostgreSQL 11. That is still the case in SQL Server and SQLite, by the way. PostgreSQL 11 supports all frame units with all boundary types.
Even the last frame unit, groups, is fully supported by PostgreSQL 11. Groups assigns each row of the result or partition into a group just like the group by clause does. The <distance> then refers to the number of groups to cover before and after the current row, i.e. the number of distinct sort key values.
The following figure shows how the groups frame covers one distinct value before the current value (1 preceding) and the current value itself (current row). The numeric difference between the values does not matter, nor does the number of rows. Groups is solely about the number of distinct values.
PostgreSQL 11 is the first major SQL database to support groups frames.
Frame Exclusion
Another feature that is not yet implemented by any other major SQL product is frame exclusion. It removes rows from the frame that are related to the current row.
The default is exclude no others, which does not remove any rows.
The next option is to remove the current row itself from the frame.
EXCLUDE CURRENT ROW
Note that the meaning of the exclude clause is not affected by the frame unit. Current row just removes the current row—even if the range or groups unit is used and the current row has peers. This is different from the behavior of current row in a frame bound.
To remove the current row along with all its peers from the frame, use exclude group.
EXCLUDE GROUP
Again, this is independent of the frame unit and thus also removes peers when using the rows unit.
Finally, it is also possible to remove the peers of the current row, but not the current row itself:
EXCLUDE TIES
Compatibility
Create Procedure and Call
PostgreSQL has supported user-defined functions for ages. Create procedure, on the other hand, was not supported before PostgreSQL 11. Previously, returns void functions were often used to mimic procedures.
The new procedures introduced to PostgreSQL 11 differ from functions in several ways:
They cannot return anything
They are invoked by the call statement, rather than in an SQL expression
They can contain transaction control statements (in particular commit and rollback)3
There is not much more I have to say about procedures, except that it is still a work in progress topic. This is especially true for drivers like JDBC.
Despite the size of this support matrix, there are several aspects I have not tested:
Security (T323, T324)
Semantics of drop restrict|cascade (F032)
Cyclic dependencies (T655)
Collection type parameters (S201, S202)
Dynamic SQL in routines (T652)
Schema statements in routines (T651)
Overloading (T341)
Proprietary extensions such as alter procedure, drop routine, transaction control in routines, etc.
Parameters in Fetch First|Next
Fetch first N rows only is the standard SQL syntax for the well known but proprietary limit clause. It was introduced with SQL:2008 and then promptly supported by PostgreSQL in 2009 (version 8.4). However, there was one very small gotcha: the use of a parameter instead of a literal value required the parameter to be enclosed in a pair of parentheses.
FETCH FIRST ($1) ROWS ONLY
Although it is not a big deal if you know about it, it can drive you crazy when you get the error message “syntax error at or near "$1"” when you omit the parentheses.
PostgreSQL 11 accepts parameters (and expressions) without parentheses.
Relative XPath Expressions
Another small annoyance—one that was easy to live with when you knew about it—was that PostgreSQL has interpreted relative XPath expressions in XML functions as being relative to the root node of the document. Makes sense, right? Not really, it should be the document node.
SELECT c
FROM (VALUES ('<root>
<c>c1</c>
<c>c2</c>
</root>'::xml
)
) t(x)
, XMLTABLE ('root/c' -- XPath expression
PASSING x
COLUMNS c TEXT PATH '.'
)
If the XPath expression 'root/c' is interpreted relative to the document node, as mandated by the standard, it will match both <c> elements in <root>.
Until version 10, PostgreSQL evaluated those expressions relative to the root note<root>, meaning that this expression doesn’t match anything. In older releases you would either have to use the relative XPath expression 'c' or, preferably, the absolute XPath expression '/root/c' to get the same result.
Other News
The above-mentioned features that relate to the SQL standard are just a small part of the changes in PostgreSQL 11. Please have a look at the release notes for all the changes.
For your convenience, I’ll give you a little teaser:
Partitioning
Partitioning is no longer sadly incomplete. New in PostgreSQL 11:
Cross partition primary key and unique constraints
Foreign keys are supported in one way (partitioned table can refer to non-partitioned table)
Update statements can move rows to another partition
Default partitions
Hash partitioning
Parallel Processing
Improvements of existing parallel execution (Hash Join, Seq Scan).
A few more commands that can be executed in parallel: creation of b-tree indexes, create table … as select, create materialized view.
Adding a new column to an existing table is a fairly common task. If the new column has a default value of null, PostgreSQL was already able to add this column by changing only the table’s metadata. PostgreSQL 11 extends this ability to columns with a constant default value.
There is another PostgreSQL 11 feature that actually deserves its own article: create index … include. This article will be published on Use The Index, Luke! soon. Follow use-the-index-luke.com via Twitter, e-mail or RSS to get it.
If you’d like to learn more about modern SQL, have a look at my training in Vienna. In addition to window functions (mentioned above), it covers recursion and indexing, and greatly improves your understanding of basic SQL concepts. The training is based on the current draft of my next book. Check it out now!
I wrote yesterday about Vitess, a scale-out sharding solution for MySQL.
Another similar product is Citus, which is a scale-out sharding solution for PostgreSQL.
Similar to Vitess, Citus is successfully being used to solve problems of scale and performance that have previously required a lot of custom-built middleware.
This email
thread from 2017 asks the question of whether there is an imperative language that generates
declarative output that can be converted into an imperative program and executed. Specifically, is there an
imperative syntax that can output SQL (a declarative language) which can be executed internally (imperatively) by Postgres?
The real jewel in this email thread is from Peter
Geoghegan, who has some interesting comments. First, he explains why developers would want an imperative language interface, even if it has to be converted to
declarative:
Some developers don't like SQL because they don't have a good intuition for how the relational model works. While SQL does have some cruft —
incidental complexity that's a legacy of the past — any language that corrected SQL's shortcomings wouldn't be all that different to SQL, and
so wouldn't help with this general problem. QUEL wasn't successful because it was only somewhat
better than SQL was at the time.
Common table expressions, aka CTEs, aka WITH queries, are not only the gateway to writing recursive SQL queries, but also help developers write maintainable SQL. WITH query clauses can help developers who are more comfortable writing in imperative languages to feel more comfortable writing SQL, as well as help reduce writing redundant code by reusing a particular common table expressions multiple times in a query.
A new patch, scheduled to be a part of PostgreSQL 12 major release later in the year, introduces the ability, under certain conditions, to inline common table expressions within a query. This is a huge feature: many developers could suddenly see their existing queries speed up significantly, and the ability to explicitly specify when to inline (i.e. the planner "substitutes" a reference to the CTE in the main query and can then optimize further) or, conversely, materialize (i.e. place the CTE into memory but lose out on certain planning & execution optimizations).
But why is this a big deal? Before we look into the future, first let's understand how WITH queries currently work in PostgreSQL.