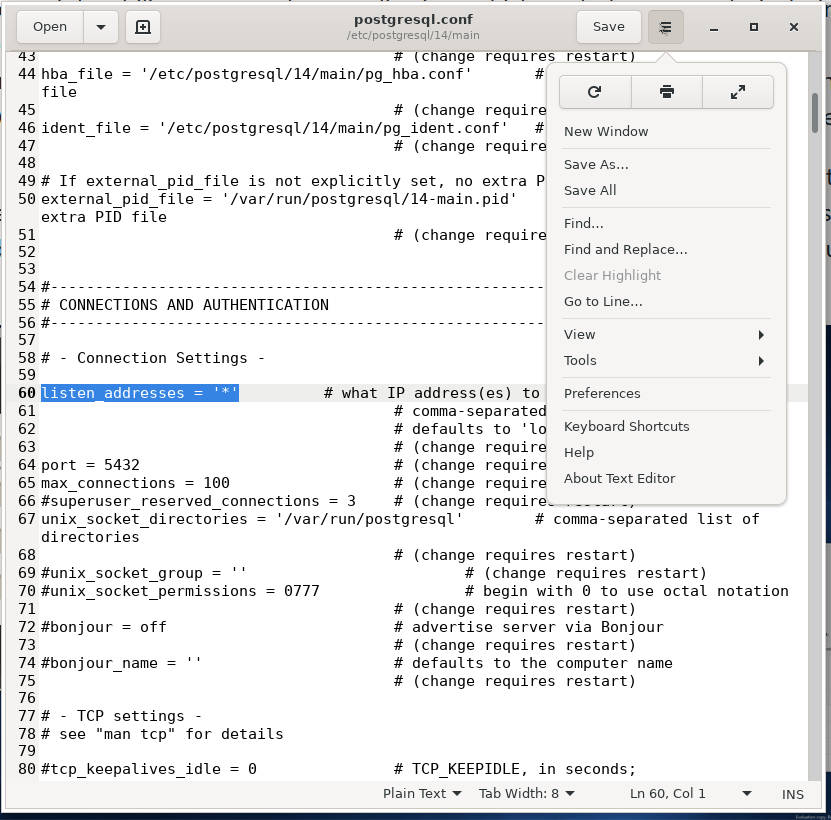
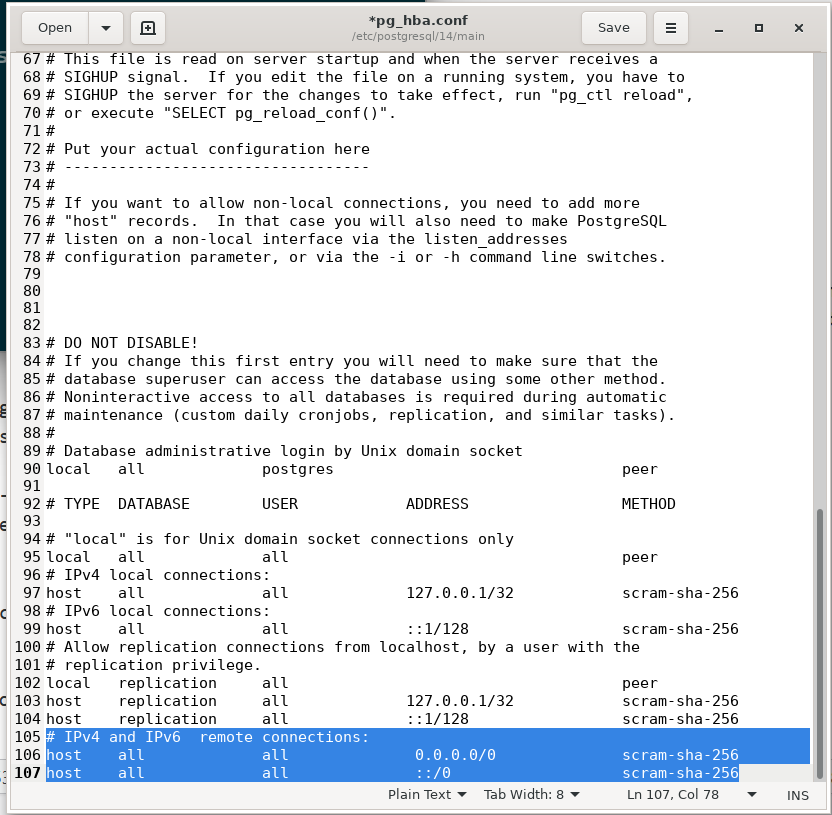
While migrating from other databases like Oracle to PostgreSQL, we may come across some functionalities that may be only available with a complex work-around. At MigOps, we have migrated many customers from Oracle to PostgreSQL and I have personally seen many scenarios where direct equivalent is not possible. One of them was while working with regular expressions. There are many regexp functions that are currently supported by PostgreSQL. However, there are some regexp functions that are currently missing. For this reason, I have contributed to a patch and with that, PostgreSQL 15 will include some more regexp functions. In this article, I am going to talk about new regexp functions that will be seen in PostgreSQL 15.
Currently existing regexp functions until PostgreSQL 14
Historically in PostgreSQL, there were a bunch of functions supporting POSIX regular expressions. Actually the total count was six as seen in the following section :
- substring ( string text FROM pattern text ) => text
Extracts the first substring matching POSIX regular expression - regexp_match ( string text, pattern text [, flags text ] ) => text[]
Returns captured substrings resulting from the first match of a POSIX regular expression to the string - regexp_matches ( string text, pattern text [, flags text ] ) => setof text[]
Returns captured substrings resulting from the first match of a POSIX regular expression to the string, or multiple matches if the g flag is used - regexp_replace ( string text, pattern text, replacement text [, flags text ] ) => text
Replaces substrings resulting from the first match of a POSIX regular expression, or multiple substring matches if the g flag is used - regexp_split_to_array ( string text, pattern text [, flags text ] ) => text[]
Splits string using a POSIX regular expression as the delimiter, producing an array of results - regexp_split_to_table ( string text, pattern text [, flags text ] ) => setof text
Splits string using a POSIX regular expression as the delimiter, producing a set of results
I am not including any examples of how to use these functions in this article as I am only going to talk about the PostgreSQL 15 features surrounding new regexp functions. Meanwhile, you could see the PostgreSQL documentation for more understanding of these existing regexp functions.
Although there was a limited number of functions, they allow us to perform most of the common work with regular expression in SQL queries or stored procedures.
But what if you want to count the number of times a pattern is found in a string? Or the position of the pattern in the string ? Or you want to start the pattern search at a specific position in the string ? That's not too difficult to code using the PostgreSQL functions but the query becomes less readable. Now suppose that you want to work only on the Nth occurrence of a pattern matching, that becomes much more complicated.
The SQL standard XQuery specification since 2008 define some other regexp functions with the LIKE_REGEX predicate and the OCCURENCES_REGEX, POSITION_REGEX, SUBSTRING_REGEX and TRANSLATE_REGEX functions. They are better known under the name of REGEXP_LIKE, REGEXP_COUNT, REGEXP_INSTR, REGEXP_SUBSTR and REGEXP_REPLACE. These are the common names used in most RDBMS or other software using the XQuery specifications.
Until now, REGEXP_SUBSTR and REGEXP_REPLACE were not available in PostgreSQL but existing functions regexp_match(es), substring and regexp_replace can be used to implement the missing functions. This can be a complicated work especially to code the Nth occurrence behaviour, considering the performances loss compared to a native implementation. I understand the effort it needs very well as I have implemented these plgsql functions in orafce for Oracle compatibility.
New regexp functions in PostgreSQL 15
To extend the possibilities to play with regular expression in PostgreSQL, I have implemented the following new regexp native functions. They will be available in PostgreSQL 15.
- regexp_count ( string text, pattern text [, start integer [, flags text ] ] ) => integer
![PostgreSQL 15 regexp functions]()
Returns the number of times the POSIX regular expression pattern matches in the string - regexp_instr ( string text, pattern text [, start integer [, N integer [, endoption integer [, flags text [, subexpr integer ] ] ] ] ] ) => integer
Returns the position within string where the N'th match of the POSIX regular expression pattern occurs, or zero if there is no such match - regexp_like ( string text, pattern text [, flags text ] ) => boolean
Checks whether a match of the POSIX regular expression pattern occurs within string - regexp_substr ( string text, pattern text [, start integer [, N integer [, flags text [, subexpr integer ] ] ] ] ) => text
Returns the substring within string that matches the N'th occurrence of the POSIX regular expression pattern, or NULL if there is no such match

And I have also extended the following functions to allow a start position to be used and a matching occurrence or sub-expression for regexp_replace :
- regexp_match ( string text, pattern text [, flags text ] ) => text[]
Returns substrings within the first match of the POSIX regular expression pattern to the string; - regexp_matches ( string text, pattern text [, flags text ] ) => setof text[]
Returns substrings within the first match of the POSIX regular expression pattern to the string, or substrings within all such matches if the g flag is used - regexp_replace ( string text, pattern text, replacement text [, start integer ] [, flags text ] ) => text
Replaces the substring that is the first match to the POSIX regular expression pattern, or all such matches if the g flag is used - regexp_replace ( string text, pattern text, replacement text, start integer, N integer [, flags text ] ) => text
Replaces the substring that is the N'th match to the POSIX regular expression pattern, or all such matches if N is zero;
For example, the following syntax is used until PostgreSQL 15 :
SELECT * FROM contact
WHERE (regexp_match(email, '^(pgsql-[^@]+@[^.]+\.[^.]+.*)', 'i'))[1] IS NOT NULL;With PostgreSQL 15, you can now use the following syntax implementing regexp_like :
SELECT * FROM contact
WHERE regexp_like(email, '^pgsql-[^@]+@[^.]+\.[^.]+.*', 'i');Or to count the number of time a sting is matching a pattern, following syntax is used until PostgreSQL 14 :
SELECT count(*) FROM regexp_matches( documents, '(postgresql|postgres)', 'ig');But with PostgreSQL 15, it can be simply written as seen in the following command.
SELECT regexp_count(documents, '(postgresql|postgres)', 'ig');Let us consider that you are looking to fix data import with an attribute containing multiple values character and you want to remove the 4th occurrence of the sub-expression Y or N in the value. This will require a lot of plpgsql code to be able to do that but with new extended version of regexp_replace() you can now write it as following :
SELECT regexp_replace('123|Y|PAN|N|45|Y|Y|EI', '(Y|N)\|', '', 1, 4);
regexp_replace
---------------------
123|Y|PAN|N|45|Y|EI
(1 row)This is not a common use for regular expressions but when it happens, it saves time with such a feature in PostgreSQL 15. And obviously, it also helps if you want to migrate from other RDBMS that has already got these regexp functions implemented. When you will be migrating to PostgreSQL 15 in the future, you should make sure that you verify whether they have the same behaviour similar to the existing application, as it may not be at all times. Usually, you can easily fix any such behavioural changes by using the right flags (regexp modifiers). See the PostgreSQL devel documentation and especially the last section about the differences between the POSIX-based regular-expression feature and XQuery regular expressions.
I want to thank Tom Lane for the work on the deeper integration of this code to PostgreSQL core and all the work to improve regular expressions in PostgreSQL.
Contact MigOps for Migrations to PostgreSQL
We get a lot of ideas from the migrations we do from Oracle to PostgreSQL or any other database like SQL Server or DB2 or Sybase to PostgreSQL. We see whether these missing functionalities can be contributed to an Open Source PostgreSQL extension or to PostgreSQL. If you are looking to migrate to PostgreSQL and require any support, please contact us at : sales@migops.com or fill the following form.
Our Recent Articles
- PostgreSQL 15 will include some more regexp functions
- MigOps announcing the support for Babelfish on any Cloud Platform
- Migration Management and schema version control in PostgreSQL
- Organizing PostgreSQL codebase using templates in Golang
- Stored Procedure OUT Parameters in PostgreSQL 14
The post PostgreSQL 15 will include some more regexp functions appeared first on MigOps.


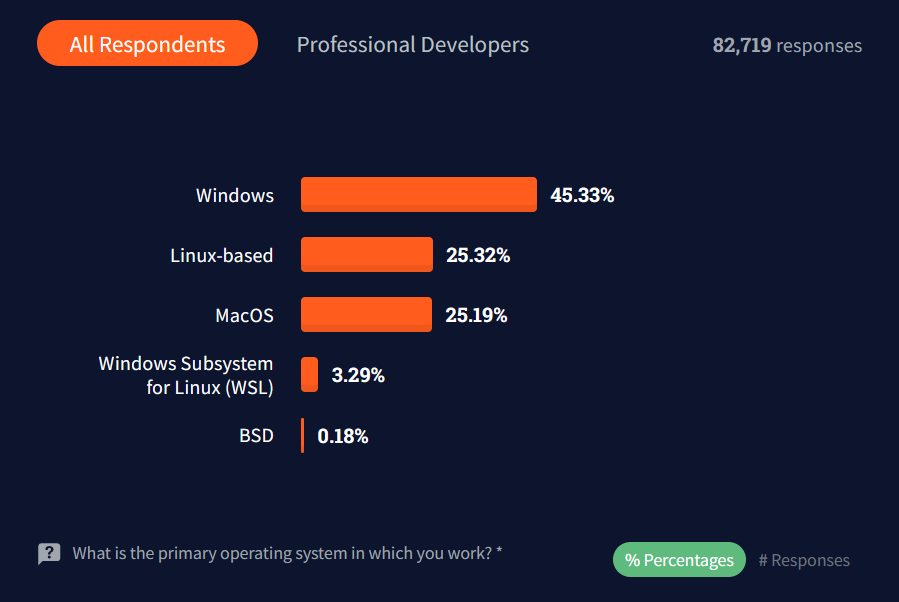
 All further commands are supposed to be executed in the Ubuntu WSL2 session.
All further commands are supposed to be executed in the Ubuntu WSL2 session. I’m aware that the newest WSL2 version allows localhost forwarding, but I think this topic is essential to know, especially in constructing a development environment!
I’m aware that the newest WSL2 version allows localhost forwarding, but I think this topic is essential to know, especially in constructing a development environment!